
在网络爬取中使用 Amazon AWS WAF CAPTCHA
Amazon(AWS WAF)CAPTCHA 与 Challenge —— 它们是什么以及有什么区别
AWS WAF(亚马逊提供的服务)为防止网站受到自动化恶意行为,提供了两种主要的防护方式:
CAPTCHA —— 要求用户完成一些任务,例如:在输入框中输入文本、拖动滑块、在图片中选择指定对象,或将元素拖动到指定位置。同时也可能提供音频验证码,用户需要在噪声背景中识别并输入听到的词语。
Amazon CAPTCHA 示例:
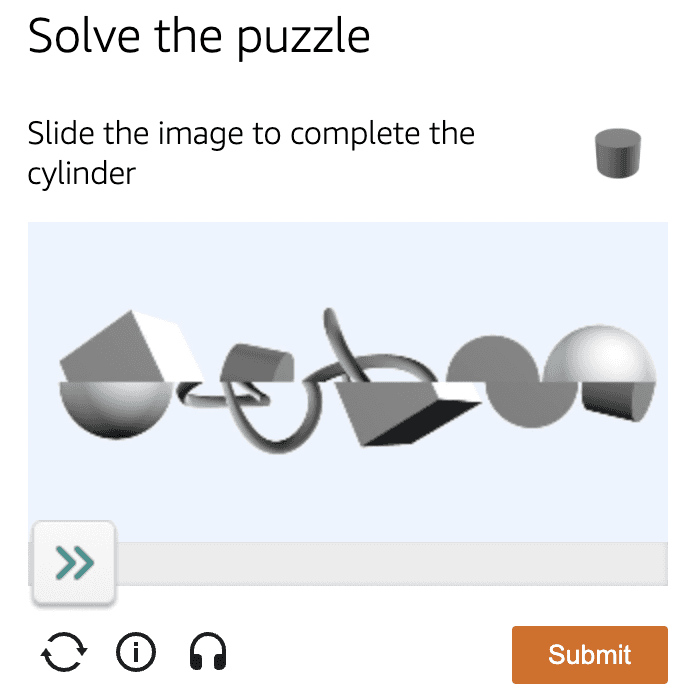
滑块形式的 Amazon CAPTCHA
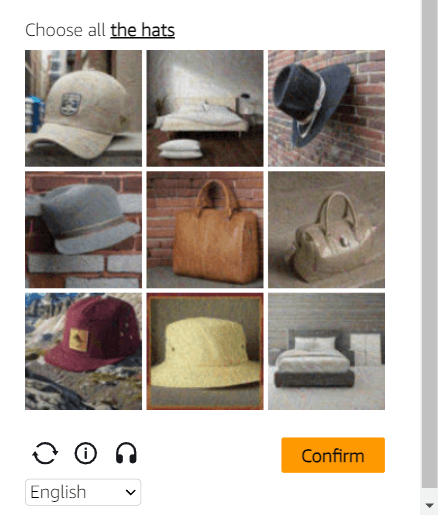
对象选择

拖动元素
Challenge —— 在这种情况下,用户无需进行任何解谜操作,验证在后台完成。系统会分析会话参数和请求行为(例如请求频率、JavaScript 使用情况、鼠标行为、Cookie 的存在与否)。如果验证通过,用户可以继续访问网站;如果未通过,请求可能被阻止,或者系统会进一步显示 CAPTCHA 进行额外验证。如果系统检测到自动化行为迹象,可能会提高验证等级,以确保网站安全并防止未授权访问。
如何使用 CapMonster Cloud 解决 Amazon 验证码
Amazon 的安全防护系统经过精心设计,提供了很高的安全级别,并且会不断更新,从而增加机器人访问网站的难度。然而,在网站测试、安全数据抓取以及调试的目的下,可以使用云服务 CapMonster Cloud 来绕过这些限制。
验证码数据的获取
要解决此类验证码,需要进入带有验证码的目标网站,打开 开发者工具,并获取必要的验证码参数——websiteKey、context、iv 和 challengeScript。
以下是更详细的操作说明:
加载目标页面,打开 开发者工具,切换到 网络(Network) 标签页,并找到状态码为 405 的文档请求:
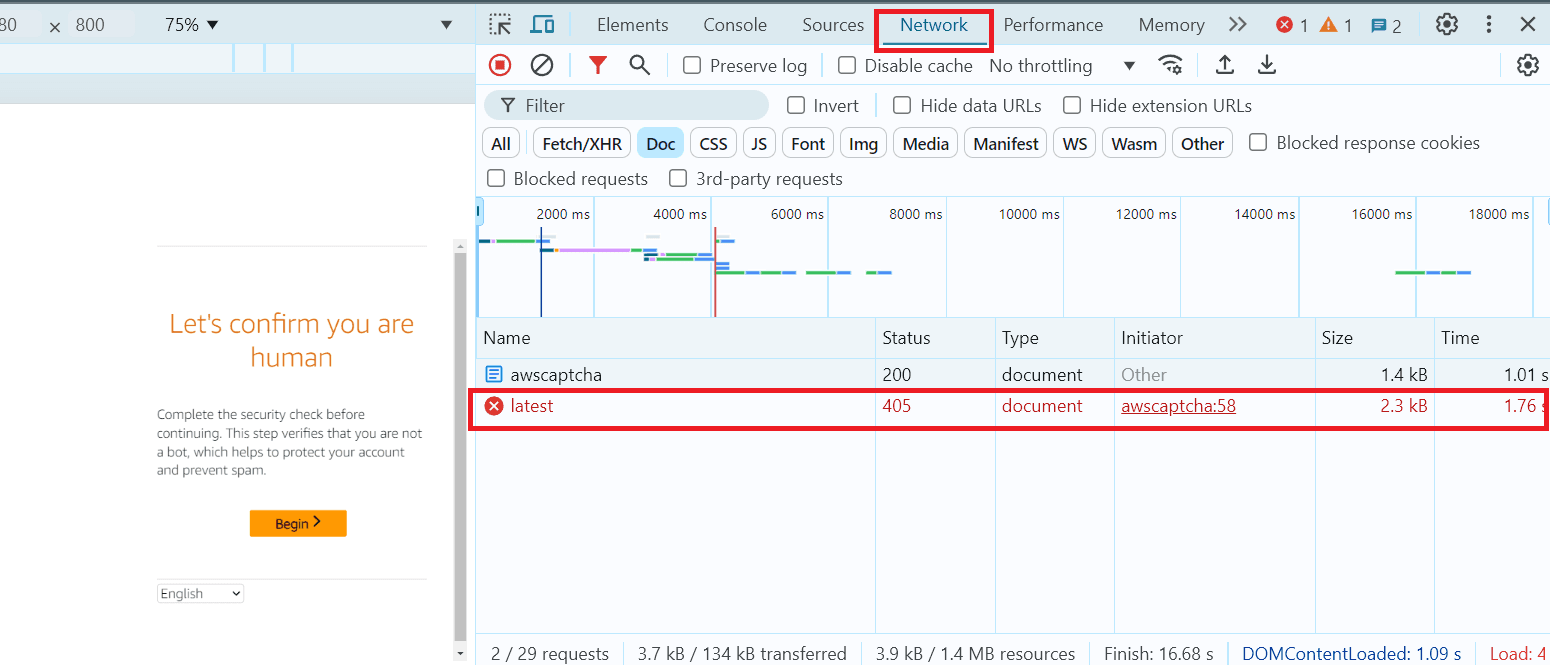
选择该请求并进入 Response 标签页:
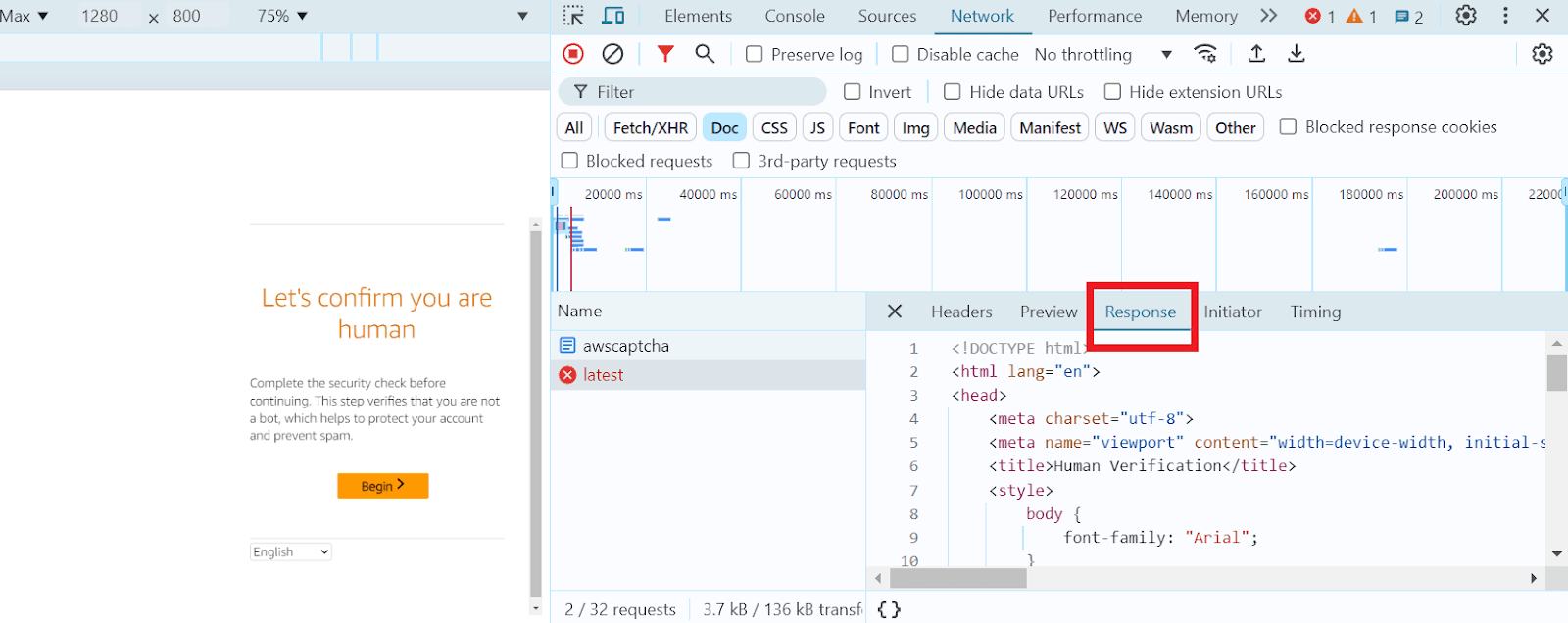
找到对象 window.gokuProps,其中包含所有必要的参数:
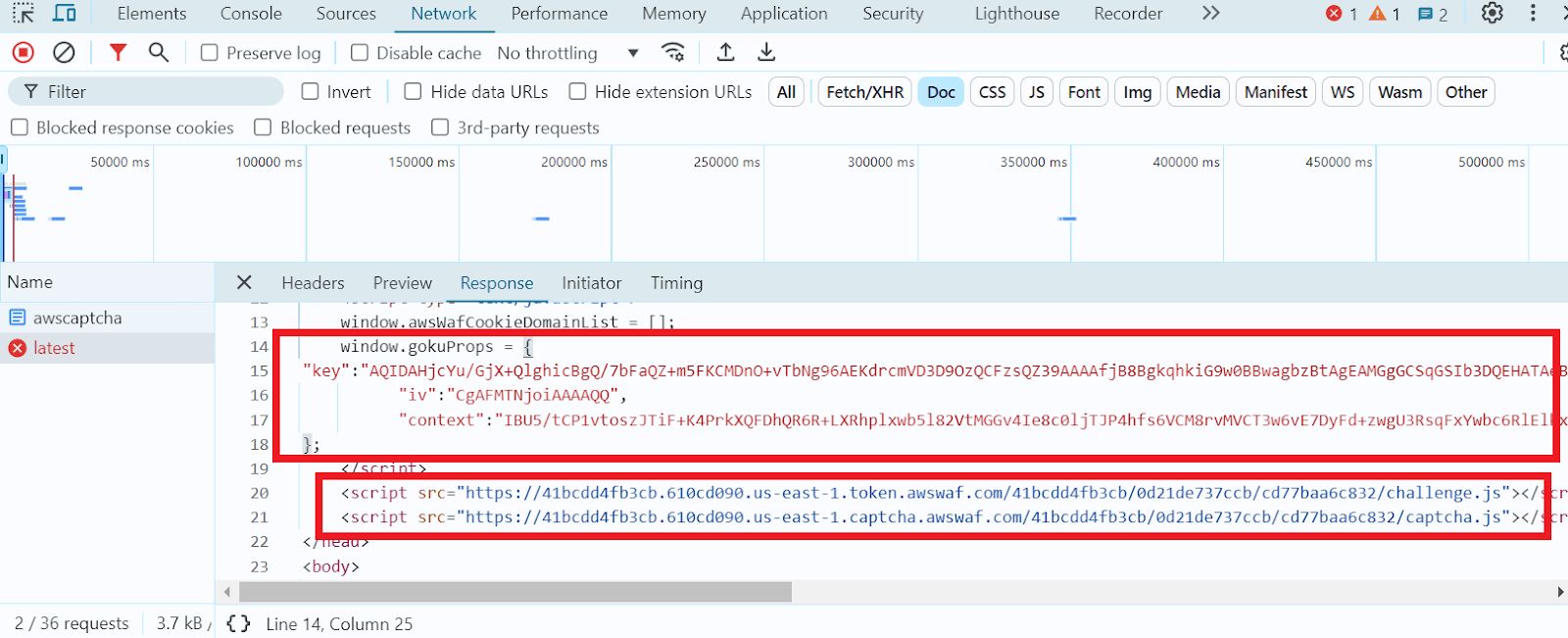
必需参数及其取值表
| 参数 | 类型 | 是否必填 | 值 |
| type | String | 是 | AmazonTask |
| websiteURL | String | 是 | 出现验证码的目标页面地址 |
| challengeScript | String | 是 | challenge.js 的链接 |
| captchaScript | String | 是 | captcha.js 的链接 |
| websiteKey | String | 是 | 可从验证码页面 HTML 或 window.gokuProps.key 获取 |
| context | String | 是 | 可从验证码页面 HTML 或 window.gokuProps.context 获取 |
| iv | String | 是 | 可从验证码页面 HTML 或 window.gokuProps.iv 获取 |
| cookieSolution | Boolean | 否 | 默认 false。如需 aws-waf-token cookie,请设置为 true。否则将返回 captcha_voucher 和 existing_token。 |
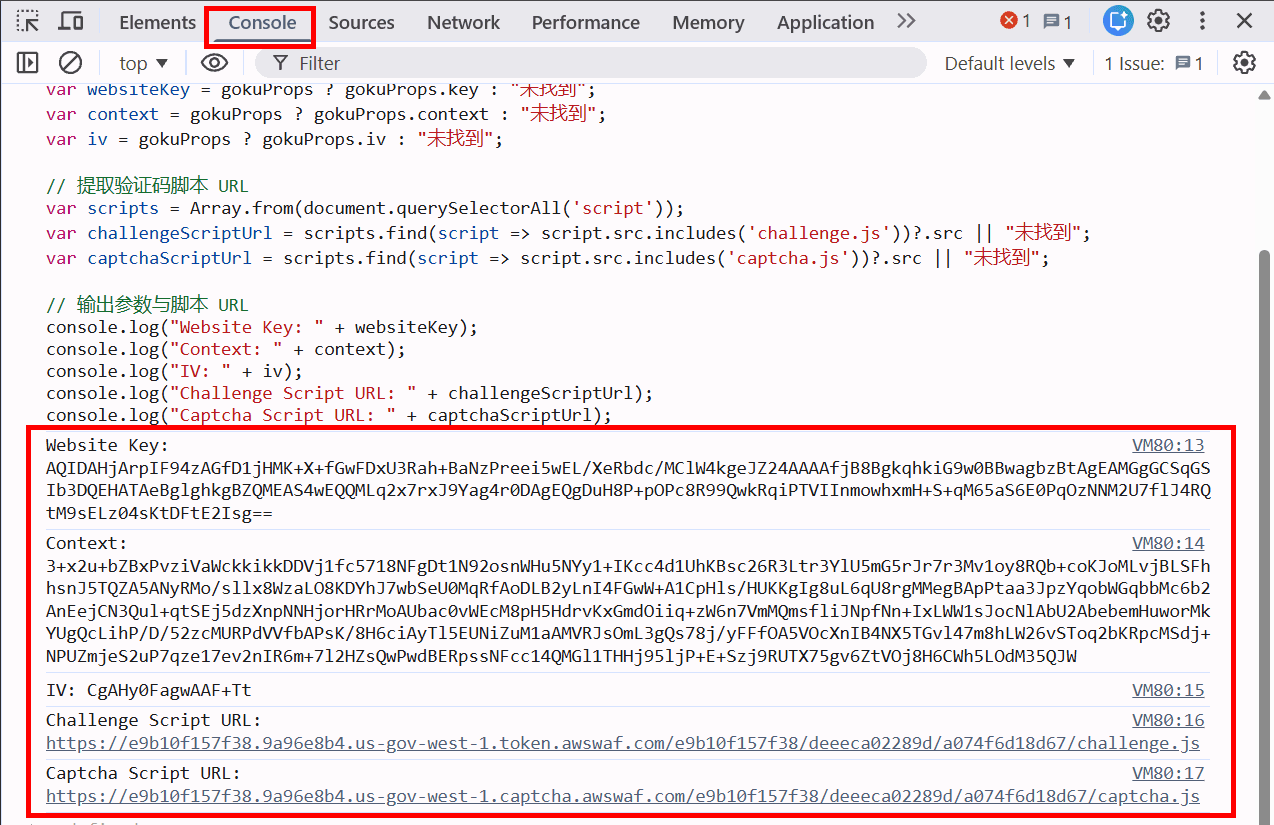
您还可以使用以下 JavaScript 代码自动获取 AWS WAF 验证码参数:
// 提取验证码参数
var gokuProps = window.gokuProps;
var websiteKey = gokuProps ? gokuProps.key : "未找到";
var context = gokuProps ? gokuProps.context : "未找到";
var iv = gokuProps ? gokuProps.iv : "未找到";
// 提取验证码脚本 URL
var scripts = Array.from(document.querySelectorAll('script'));
var challengeScriptUrl = scripts.find(script => script.src.includes('challenge.js'))?.src || "未找到";
var captchaScriptUrl = scripts.find(script => script.src.includes('captcha.js'))?.src || "未找到";
// 输出参数与脚本 URL
console.log("Website Key: " + websiteKey);
console.log("Context: " + context);
console.log("IV: " + iv);
console.log("Challenge Script URL: " + challengeScriptUrl);
console.log("Captcha Script URL: " + captchaScriptUrl);
创建请求、发送任务到服务器、获取结果
当你已经获取到所有验证码参数后,就可以构建任务并发送到 CapMonster Cloud 服务器。
请求示例:
请求地址: https://api.capmonster.cloud/createTask
请求格式:JSON POST
{
"clientKey": "API_KEY",
"task": {
"type": "AmazonTask",
"websiteURL": "https://example.com",
"challengeScript": "https://41bcdd4fb3cb.610cd090.us-east-1.token.awswaf.com/41bcdd4fb3cb/0d21de737ccb/cd77baa6c832/challenge.js",
"captchaScript": "https://41bcdd4fb3cb.610cd090.us-east-1.captcha.awswaf.com/41bcdd4fb3cb/0d21de737ccb/cd77baa6c832/captcha.js",
"websiteKey": "AQIDA...wZwdADFLWk7XOA==",
"context": "qoJYgnKsc...aormh/dYYK+Y=",
"iv": "CgAAXFFFFSAAABVk",
"cookieSolution": true
}
}
响应示例:
{
"errorId": 0,
"taskId": 407533072
}
获取结果:
使用方法 getTaskResult, 用于获取 AmazonTask 的解答结果
https://api.capmonster.cloud/getTaskResult
响应示例:
{
"errorId": 0,
"status": "ready",
"solution": {
"cookies": {
"aws-waf-token": "10115f5b-ebd8-45c7-851e-cfd4f6a82e3e:EAoAua1QezAhAAAA:dp7sp2rXIRcnJcmpWOC1vIu+yq/A3EbR6b6K7c67P49usNF1f1bt/Af5pNcZ7TKZlW+jIZ7QfNs8zjjqiu8C9XQq50Pmv2DxUlyFtfPZkGwk0d27Ocznk18/IOOa49Rydx+/XkGA7xoGLNaUelzNX34PlyXjoOtL0rzYBxMAQy0D1tn+Q5u97kJBjs5Mytqu9tXPIPCTSn4dfXv5llSkv9pxBEnnhwz6HEdmdJMdfur+YRW1MgCX7i3L2Y0/CNL8kd8CEhTMzwyoXekrzBM="
},
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/147.0.0.0 Safari/537.36"
}
}
用于网页抓取时解决 Amazon 验证码的 Python 示例代码:
在网页抓取过程中,可能会遇到各种阻碍,例如由于目标网站出现 Amazon 验证码而导致脚本暂停。为了解决这个问题,你可以在爬虫中添加额外代码,用于自动识别并解决验证码,该代码会等待验证码 iframe 加载,自动提取所有必要参数,并将结果发送到 CapMonster Cloud 服务器。
实现方式如下:假设我们有一个使用 Selenium 的 Python 天气网站抓取脚本:
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
try:
# 打开天气主页
driver.get('https://example.com')
# 查找城市输入框,输入城市名称
search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "header-location-search")) # 请替换为实际值
)
search_box.send_keys("Moscow") # 请替换为实际值
search_box.send_keys(Keys.RETURN)
# 等待搜索结果页面加载
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.locations-list')) # 请替换为实际值
)
# 点击第一个搜索结果
first_result = driver.find_element(By.CSS_SELECTOR, 'div.locations-list a') # 请替换为实际值
first_result.click()
在同一页面中需要解决 Amazon 验证码,请添加验证码处理代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import requests
import time
# CapMonster Cloud API KEY
API_KEY = os.getenv('CAPMONSTER_API_KEY')
CREATE_TASK_URL = 'https://api.capmonster.cloud/createTask'
GET_TASK_RESULT_URL = 'https://api.capmonster.cloud/getTaskResult'
def create_task(website_key, context, iv, challenge_script_url, captcha_script_url):
print("创建任务中...")
task_data = {
"clientKey": API_KEY,
"task": {
"type": "AmazonTask",
"websiteURL": 'https://example.com', # 请替换为实际值
"challengeScript": challenge_script_url,
"captchaScript": captcha_script_url,
"websiteKey": website_key,
"context": context,
"iv": iv,
"cookieSolution": False # 如需 aws-waf-token cookie 请改为 True
}
}
response = requests.post(CREATE_TASK_URL, json=task_data)
response_json = response.json()
if response_json['errorId'] == 0:
print(f"任务创建成功。Task ID: {response_json['taskId']}")
return response_json['taskId']
else:
print(f"创建任务失败: {response_json['errorCode']}")
return None
def get_task_result(task_id):
print("获取任务结果中...")
result_data = {"clientKey": API_KEY, "taskId": task_id}
while True:
response = requests.post(GET_TASK_RESULT_URL, json=result_data)
response_json = response.json()
if response_json['status'] == 'ready':
print(f"任务完成: {response_json}")
return response_json
elif response_json['status'] == 'processing':
print("任务仍在处理中...")
time.sleep(5)
else:
print(f"获取结果失败: {response_json['errorCode']}")
return response_json
# 启动浏览器
driver = webdriver.Chrome()
try:
print("打开页面...")
driver.get('https://example.com')
# 输入城市
search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "header-location-search"))
)
search_box.send_keys("Moscow") # 请替换为实际城市
search_box.send_keys(Keys.RETURN)
# 等待 CAPTCHA iframe
print("等待 iframe...")
iframe = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'iframe[src*="execute-api"]'))
)
driver.switch_to.frame(iframe)
print("等待验证码并提取参数...")
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#captcha-container'))
)
goku_props = driver.execute_script("return window.gokuProps;")
website_key = goku_props["key"]
context = goku_props["context"]
iv = goku_props["iv"]
challenge_script_url, captcha_script_url = [
driver.execute_script(f"return document.querySelector('script[src*=\"{x}\"]').src;")
for x in ("challenge.js", "captcha.js")
]
# 创建验证码任务
task_id = create_task(website_key, context, iv, challenge_script_url, captcha_script_url)
if task_id:
result = get_task_result(task_id)
# 继续抓取结果
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.locations-list'))
)
first_result = driver.find_element(By.CSS_SELECTOR, 'div.locations-list a')
first_result.click()
finally:
print("关闭浏览器...")
driver.quit()
更新后代码的详细说明:
额外导入库 requests(用于与 CapMonster Cloud API 通信)以及 time(用于延时等待)。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import requests
import time定义 API KEY 以及 CapMonster Cloud 的请求地址。
API_KEY = os.getenv('CAPMONSTER_API_KEY')
CREATE_TASK_URL = 'https://api.capmonster.cloud/createTask'
GET_TASK_RESULT_URL = 'https://api.capmonster.cloud/getTaskResult'创建任务函数:向 CapMonster Cloud 发送验证码任务数据,并返回 taskId。
def create_task(website_key, context, iv, challenge_script_url, captcha_script_url):
# ... 函数代码获取任务结果函数:轮询任务状态,直到返回 ready。
def get_task_result(task_id):
# ... 函数代码启动浏览器并输入城市,等待页面加载结果。
search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "header-location-search"))
)
search_box.send_keys("Moscow")
search_box.send_keys(Keys.RETURN)进入 iframe 并提取 AWS WAF 验证码参数。
iframe = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'iframe[src*="execute-api"]'))
)
driver.switch_to.frame(iframe)
goku_props = driver.execute_script("return window.gokuProps;")
website_key = goku_props["key"]
context = goku_props["context"]
iv = goku_props["iv"]提交验证码任务并获取结果。
task_id = create_task(website_key, context, iv, challenge_script_url, captcha_script_url)
if task_id:
result = get_task_result(task_id)继续执行页面抓取逻辑。
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.locations-list'))
)
first_result = driver.find_element(By.CSS_SELECTOR, 'div.locations-list a')
first_result.click()
建议与推荐
上述代码仅作为示例,用于展示执行操作的一般逻辑。所有操作以及元素名称都取决于具体网站及其结构。您需要研究目标网站的 HTML 代码,并熟悉您计划使用的网页抓取工具的文档。每个网站都是独特的,因此在进行成功抓取时,可能需要根据目标资源的特点对代码和方法进行调整。同时,Amazon 的验证码也有其特殊性,需要加以考虑。
以下是一些用于成功进行网页抓取以及绕过 Amazon CAPTCHA(AWS WAF)的通用建议:
异步性。在我们的简单抓取示例中并未使用异步方法。然而,如果您处理大量数据或访问响应较慢的网站,建议使用异步编程,以便并行执行任务并提高效率。
无头模式。在无头模式下运行浏览器可以提高速度并节省资源。在没有图形界面的情况下,处理过程可能更加高效。
图形化浏览器。如果网站需要复杂交互,请使用带界面的浏览器。这有助于更好地处理界面元素、测试代码,并避免某些错误和封锁。
更换 IP 地址与 User-Agent。为了避免被网站封锁或限制,应定期更换 IP 地址和 User-Agent。使用高质量代理服务器,并在请求中轮换 User-Agent,以避免被识别为自动化行为。
动态 CAPTCHA 处理。Amazon 使用的验证码可能会根据时间或用户行为变化,并不断更新其反爬机制。请确保脚本能够适应这些变化并正确处理验证码,同时关注相关更新。
降低请求频率。不要发送过于频繁的请求,以免触发 Amazon 的反机器人机制,或通过多个 IP 分散请求。
有用链接:
总结
Amazon(AWS WAF)验证码在数据采集中可能会带来较大挑战。然而,了解该系统的基本工作原理并使用合适的工具,可以有效应对这些问题。
我们介绍了关键要点,包括该类型验证码的说明及使用 CapMonster Cloud 的处理方式。关键步骤包括:准确提取验证码参数、在服务器上创建并提交任务,以及获取并使用验证码结果。我们还提供了 Python 示例代码,展示如何在网页抓取流程中集成验证码解决方案。该领域的成功不仅依赖技术能力,还需要快速适应反爬机制变化的能力。
备注:请注意,该产品仅用于对您自己拥有合法访问权限的网站和资源进行自动化测试。

以及如何解决它?")
:新增自动提交功能")



