
使用 Python 和 Selenium 进行网站抓取:基础与自动化
如今,信息的重要性达到了前所未有的高度,从互联网资源中提取和分析数据的能力变得尤为重要且广受需求。在本文中,我们将介绍使用 Python 和 Selenium 进行网页抓取的基础知识,并讨论 CapMonster Cloud 技术如何帮助应对各种验证码带来的挑战。您将了解这些工具如何显著提升您从互联网获取和处理数据的能力,为研究、数据分析以及流程自动化开启新的可能性。

网页抓取(web scraping)是从网页中提取数据的过程。该过程通常涉及使用程序或脚本来获取网站上展示的信息,这些信息可以应用于不同领域和用途。例如,用于比较竞争对手的价格和服务、分析消费者偏好、监控各类新闻和事件等等。
网页抓取的工作流程包括:
确定目标:在第一步需要明确要提取哪些信息,以及来自哪些网站资源。
分析目标网页结构:研究 HTML 代码结构,以了解所需信息存储的位置和方式,查找并确定标签、ID、class 等元素。
开发数据获取脚本:编写代码(例如使用 Python 以及用于浏览器自动化的 Selenium 库),访问网页、提取所需数据并以结构化方式保存。
数据处理:提取的数据通常需要进一步转换才能使用,例如去重、格式修正、过滤无用数据等。
数据保存:将提取并处理后的数据保存为方便使用的格式,例如 CSV、JSON 或数据库等。
此外,还需要关注目标网站的变化,以便在必要时及时更新脚本。
Python 编程语言和 Selenium 库经常被用于网页抓取,原因如下:
易于使用:Python 使用简单,并拥有大量用于网页抓取的库。
模拟用户行为并访问动态内容:使用 Selenium 可以自动化浏览器中的用户操作,包括页面滚动和点击按钮等,从而加载所需数据。
绕过反爬机制:一些网站使用特殊的防护机制,通过模拟真实用户行为可以帮助绕过这些限制。
广泛支持:庞大的社区和丰富的资源使这些工具更易于使用。
让我们来看一个简单的网页抓取脚本示例。作为示例,我们将使用页面 https://webscraper.io/test-sites/e-commerce/allinone/product/123,我们将在该商品卡片中查找 128 GB HDD 容量的价格。
如果你的电脑尚未安装 Python,请访问 Python 官方网站 并下载适用于你的操作系统(Windows、macOS、Linux)的版本。在开发环境的终端中,可以使用以下命令检查 Python 版本:
python --version接下来需要安装 Selenium,可以执行以下命令:
pip install selenium创建一个新文件并导入必要的库:
import time
from selenium import webdriver
同时需要在项目中添加 ‘By’ 类,它用于在 Selenium 中定义页面元素的查找策略:
from selenium.webdriver.common.by import By
ChromeDriver 选项(ChromeOptions)用于在使用 Selenium 自动化时配置 Chrome 浏览器的启动行为和参数。以下是其中一些常见选项:
完整参数列表可以在 这里 查看。
在本示例中我们使用了无痕模式。初始化 Chrome 驱动并打开目标商品页面:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
在 Selenium 中,可以使用 By 类提供的多种方法在网页中查找元素。这些方法允许根据不同条件定位元素,例如元素 ID、class 名称、标签名、name 属性、链接文本、XPath 或 CSS 选择器。
按 ID 查找示例:
按 class 名称查找:
按标签名查找:
按 name 属性查找:
按链接文本查找:
按 CSS 选择器查找:
按 XPath 查找:
如果需要查找多个元素,则使用 find_elements 方法代替 find_element。
在我们的示例中,需要定位“128”按钮元素的位置以及价格信息:
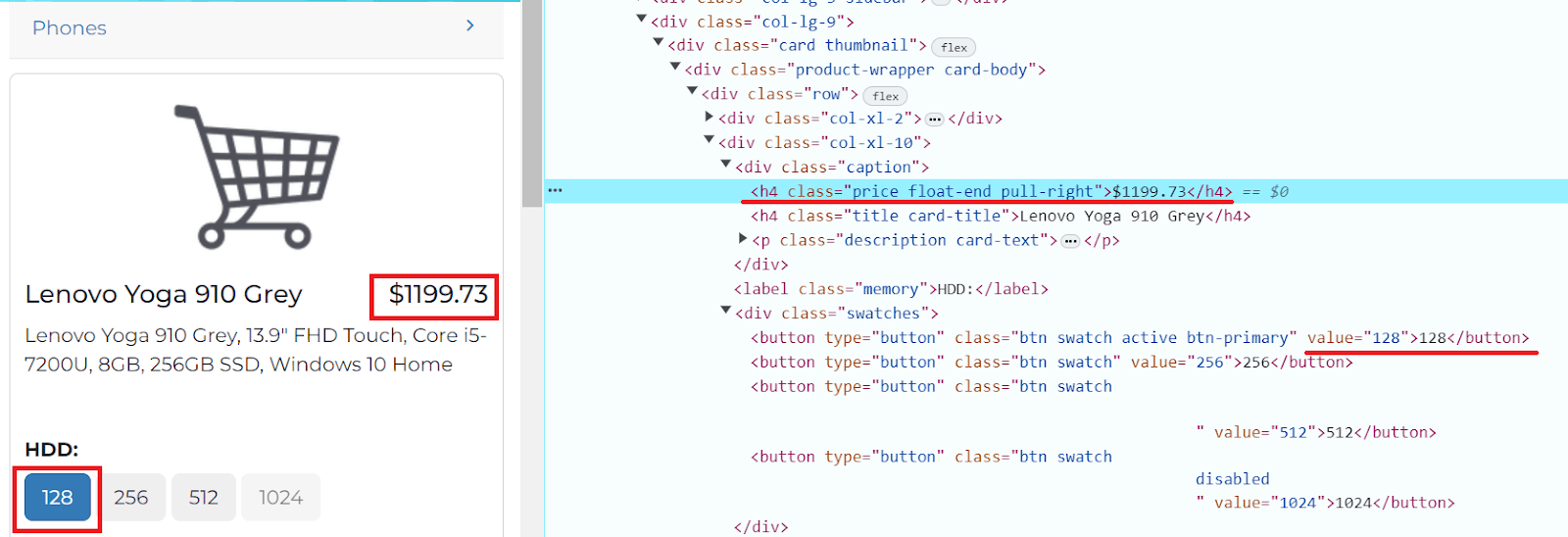
在 Selenium 中,可以通过 WebElement 对象提供的方法来模拟网页上的用户操作。这些方法允许像真实用户一样与页面元素交互,例如点击、输入文本等。
以下是一些常用方法:
回到我们的示例。使用 XPath 定位目标按钮,点击该按钮,然后查找价格元素:
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
# 等待一段时间以加载价格
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
最后在控制台输出指定 HDD 容量对应的商品价格:
price_text = price_element.text
print("商品价格:", price_text)
driver.quit()
因此,完整代码如下:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
price_text = price_element.text
print("商品价格:", price_text)
driver.quit()
在网站中经常会出现各种广告横幅和弹窗,这些元素可能会干扰脚本的执行。在这种情况下,可以配置 ChromeDriver 参数来禁用这些元素。以下是一些常见参数:
在我们示例的网站中,页面加载时会出现一个 Cookie 横幅。也可以通过其他方式将其移除,其中一种方法是使用脚本来屏蔽此类提示。首先,我们通过 开发者工具 来分析该元素:
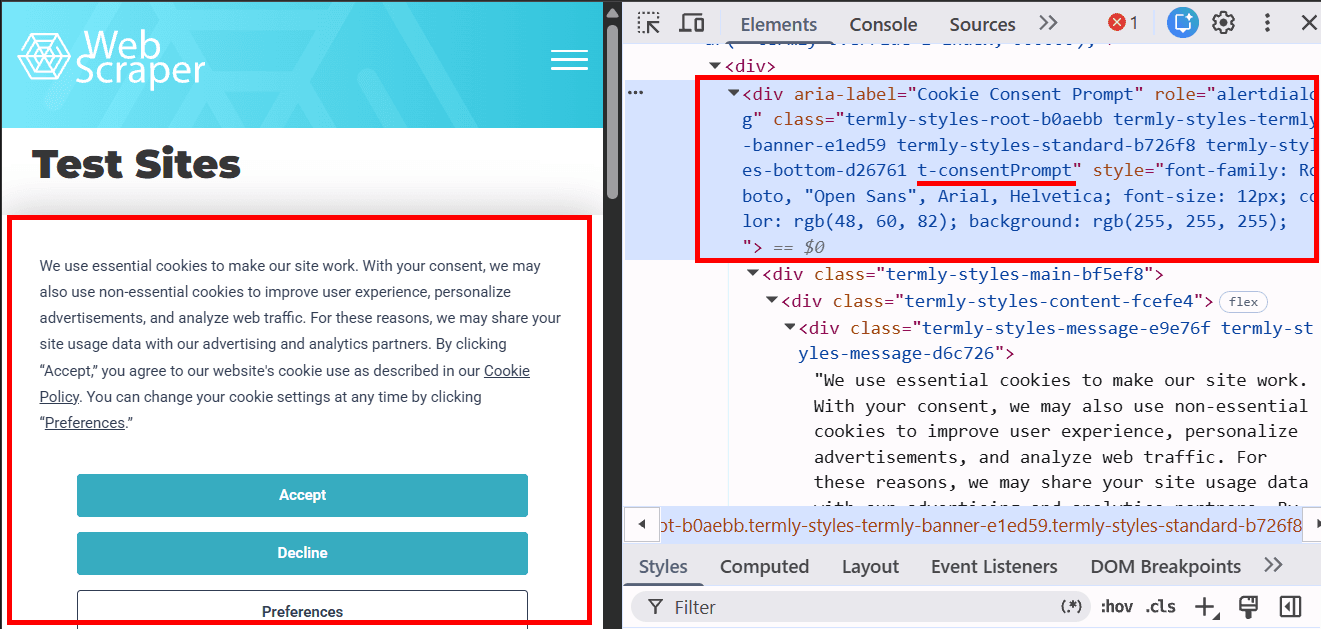
我们将使用类 .t-consentPrompt 来定位 cookie 横幅,因为这是最稳定且可读性较好的 CSS 类。像 termly-styles-root-b0aebb 这样的随机生成类在网站更新后可能会发生变化,因此通常不用于自动化。
我们通过 style.display = 'none' 来隐藏横幅,这样它就不会遮挡页面,也不会影响 Selenium 与页面元素的交互。
现在可以在脚本中加入相应逻辑来隐藏该横幅:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
# 用于隐藏 Termly cookie 横幅的脚本
script = """
var banner = document.querySelector('.t-consentPrompt');
if (banner) {
banner.style.display = 'none';
}
"""
driver.execute_script(script)
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
price_text = price_element.text
print("商品价格:", price_text)
driver.quit()另一种关闭横幅的方法是模拟用户点击“Accept”或“Decline”按钮。可以通过开发者工具检查按钮元素(例如 Accept 按钮):
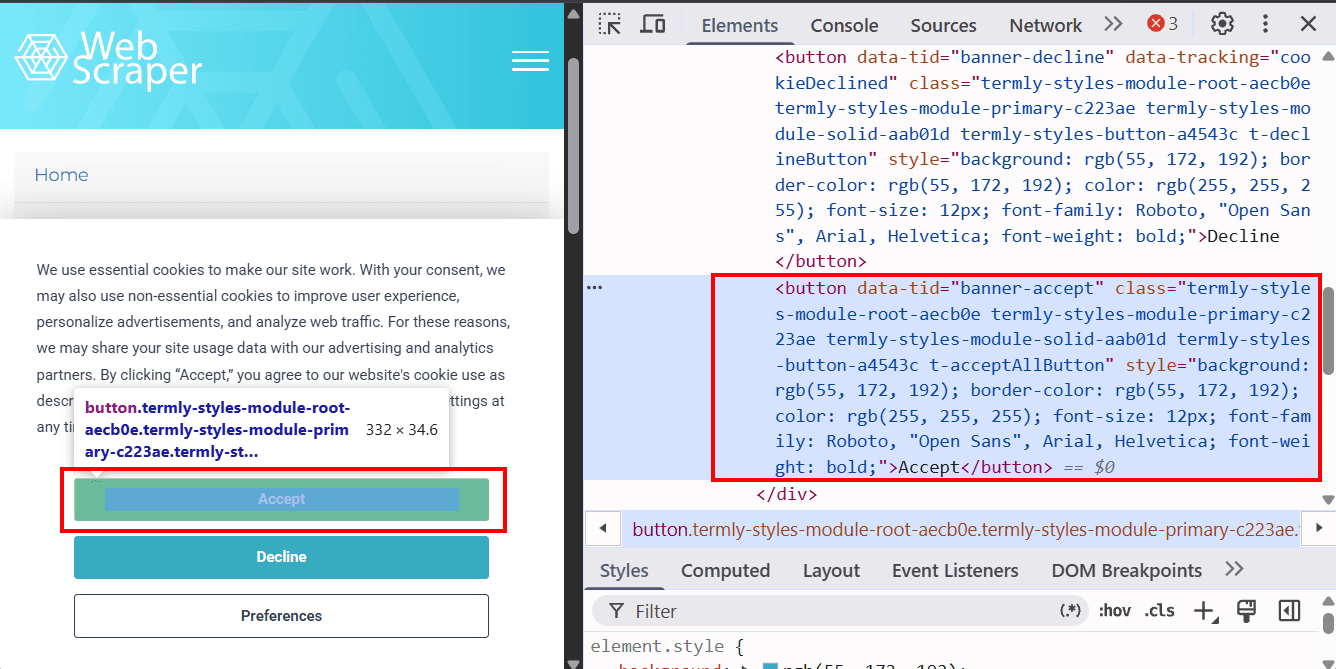
我们可以通过 data-tid="banner-accept" 来定位该按钮,并使用 button.click() 进行点击:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
# 等待 Accept 按钮并点击
accept_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(
(By.XPATH, "//button[@data-tid='banner-accept']")
)
)
accept_button.click()
# 点击 128 GB 按钮
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
# 获取价格
price_element = driver.find_element(
By.XPATH,
"//h4[@class='price float-end pull-right']"
)
price_text = price_element.text
print("商品价格:", price_text)
driver.quit()另一种有效方法是使用 Chrome 扩展程序,它可以自动接受或屏蔽所有 cookie 横幅。这些扩展可以安装到浏览器中,然后通过 ChromeOptions 加载。下载合适的 .crx 扩展,并在脚本中使用:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# .crx 扩展路径
extension_path = '/path/to/extension.crx'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
# 添加扩展
chrome_options.add_extension(extension_path)
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
price_text = price_element.text
print("商品价格:", price_text)
driver.quit()这种方法可以避免你在页面加载时手动处理这些弹窗元素。
在数据提取过程中,经常会遇到验证码这一用于防止机器人访问的安全机制。为了解决这类限制,通常会使用专门的验证码识别服务。其中一个工具是 CapMonster Cloud,它能够在极短时间内自动解决最复杂的验证码问题。该服务同时提供浏览器扩展(适用于 Chrome 和 Firefox),以及 API 方法(可在 文档中查看),可以集成到你的代码中,用于获取 token、成功绕过验证并继续执行脚本。
CapMonster Cloud 可以轻松处理的验证码类型包括:
所有类型的 reCAPTCHA

GeeTest
Cloudflare Turnstile 和 Challenge

DataDome
该脚本使用官方 CapMonster Cloud Python 库以及 Selenium,在页面上解决验证码后,提取该页面标题并将其输出到控制台:
import asyncio
from selenium import webdriver
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from capmonstercloudclient import CapMonsterClient, ClientOptions
from capmonstercloudclient.requests import RecaptchaV2Request
async def solve_captcha(api_key, page_url, site_key):
client_options = ClientOptions(api_key=api_key)
cap_monster_client = CapMonsterClient(options=client_options)
recaptcha2request = RecaptchaV2Request(websiteUrl=page_url, websiteKey=site_key)
responses = await cap_monster_client.solve_captcha(recaptcha2request)
return responses['gRecaptchaResponse']
async def parse_site_title(driver: WebDriver, url: str) -> str:
driver.get(url)
driver.implicitly_wait(10)
title_element = driver.find_element(By.TAG_NAME, 'title')
title = title_element.get_attribute('textContent')
return title
async def main():
api_key = 'YOUR_API_KEY' # 请替换为你的 CapMonsterCloud API 密钥
page_url = 'https://lessons.zennolab.com/captchas/recaptcha/v2_simple.php?level=low'
site_key = '6Lcf7CMUAAAAAKzapHq7Hu32FmtLHipEUWDFAQPY'
options = Options()
driver = webdriver.Chrome(options=options)
captcha_response = await solve_captcha(api_key, page_url, site_key)
print("验证码结果:", captcha_response)
site_title = await parse_site_title(driver, page_url)
print("页面标题:", site_title)
driver.quit()
if __name__ == "__main__":
asyncio.run(main())
使用 Python 和 Selenium 进行网页抓取可以为自动化数据采集提供大量可能性,而与 CapMonster Cloud 的集成则可以轻松绕过验证码,大幅简化数据获取流程。这些工具不仅能够提升工作效率,还能提高数据的准确性和可靠性。借助它们,你可以从电商网站到新闻站点等多种来源收集数据,用于分析、研究或构建自己的项目。同时,这一切并不一定需要深厚的编程基础——现代技术让网页抓取对初学者也变得更加友好。因此,如果你追求简单、高效与节省时间的解决方案,那么 Python、Selenium 与 CapMonster Cloud 将是一个非常理想的组合。


 CAPTCHA 和挑战")


