
Trabalhando com CAPTCHA do Amazon AWS WAF em Web Scraping
Amazon (AWS WAF) CAPTCHA e Challenge – o que são e quais são as diferenças
AWS WAF (serviço da Amazon) oferece dois principais tipos de proteção para recursos web contra ações automatizadas indesejadas:
CAPTCHA – solicita que o usuário resolva tarefas como: inserir texto em um campo específico, mover um controle deslizante, selecionar objetos em uma imagem ou mover elementos para uma posição determinada. Como alternativa, também podem ser oferecidos CAPTCHAs de áudio, nos quais o usuário deve ouvir e reconhecer palavras em meio a ruído e inseri-las no campo correspondente.
Exemplos de CAPTCHA da Amazon:
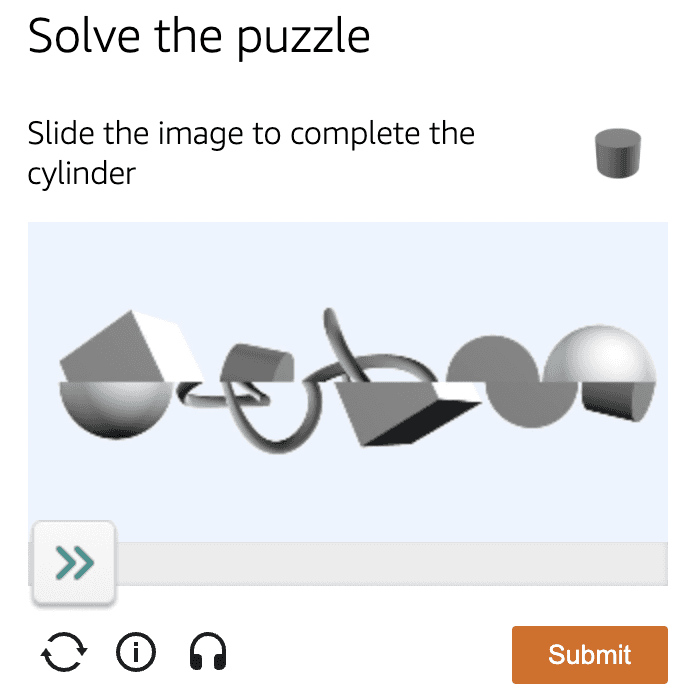
CAPTCHA da Amazon em formato de slider
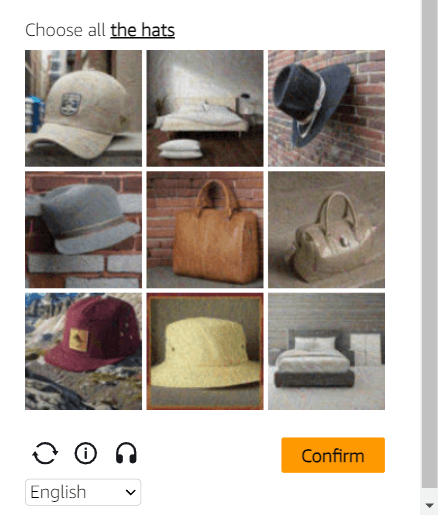
Seleção de objeto

Movimentação de elemento
Challenge – neste caso, o usuário não precisa resolver nada para interagir com o site — a verificação ocorre em segundo plano, analisando parâmetros de sessão e o comportamento das requisições (por exemplo, frequência de requisições, uso de JavaScript, comportamento do mouse, presença ou ausência de cookies). Se a verificação for bem-sucedida, o usuário continua utilizando o site; caso contrário, a requisição pode ser bloqueada ou o usuário pode receber um CAPTCHA adicional para verificação. Se o sistema detectar sinais de automação, ele pode aumentar o nível de verificação para garantir a segurança e proteger o site contra acessos não autorizados.
Como resolver CAPTCHAs da Amazon com o CapMonster Cloud
O sistema de proteção da Amazon é cuidadosamente projetado e oferece um alto nível de segurança. Ele é constantemente atualizado e torna o acesso automatizado aos sites cada vez mais difícil para bots. No entanto, para fins de teste de sites, scraping seguro e depuração, ele pode ser contornado com o serviço em nuvem CapMonster Cloud.
Localização dos dados do CAPTCHA
Para resolver esse tipo de CAPTCHA, é necessário acessar o site alvo com CAPTCHA, abrir as Ferramentas do Desenvolvedor e obter os dados necessários do CAPTCHA – websiteKey, context, iv e challengeScript.
Aqui está uma instrução mais detalhada:
Carregue a página desejada, abra as Ferramentas do Desenvolvedor, vá até a aba Rede e encontre a requisição do documento com resposta 405:
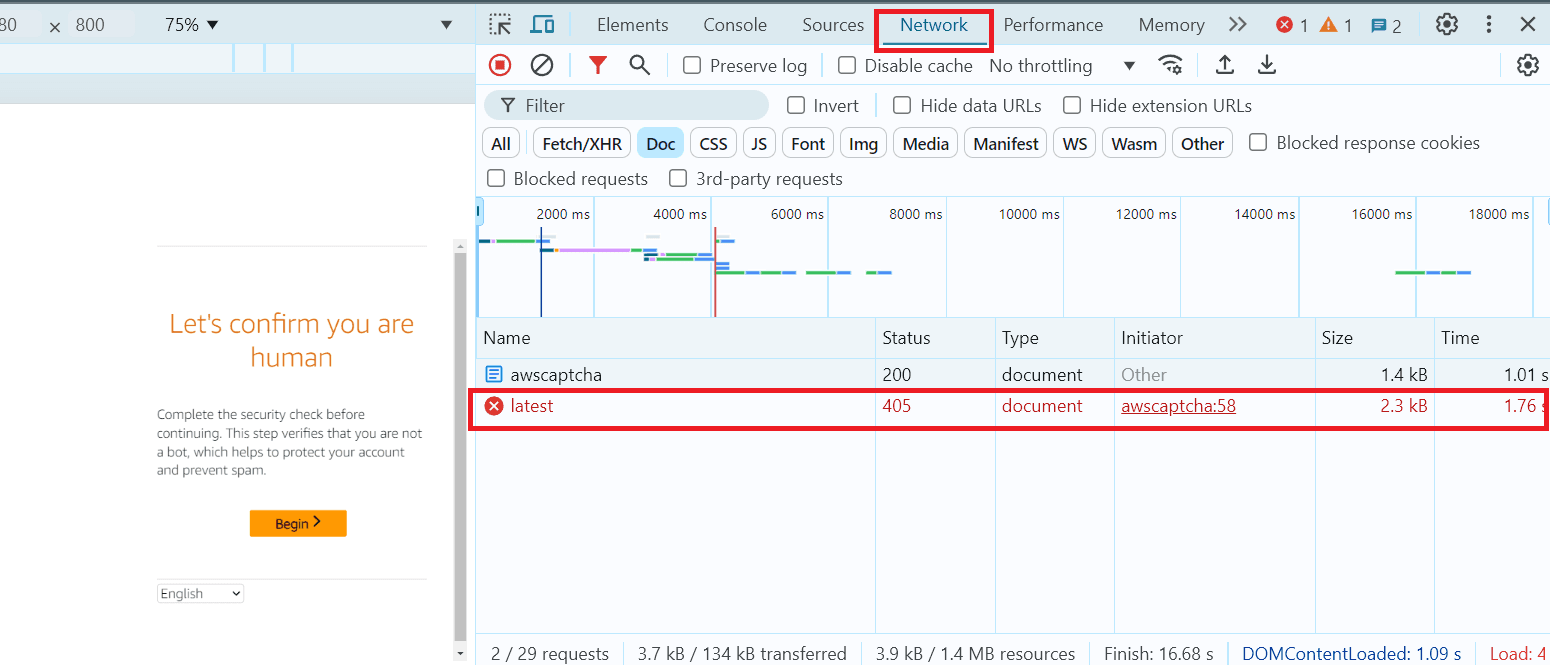
Selecione esse documento e vá para a aba Response:
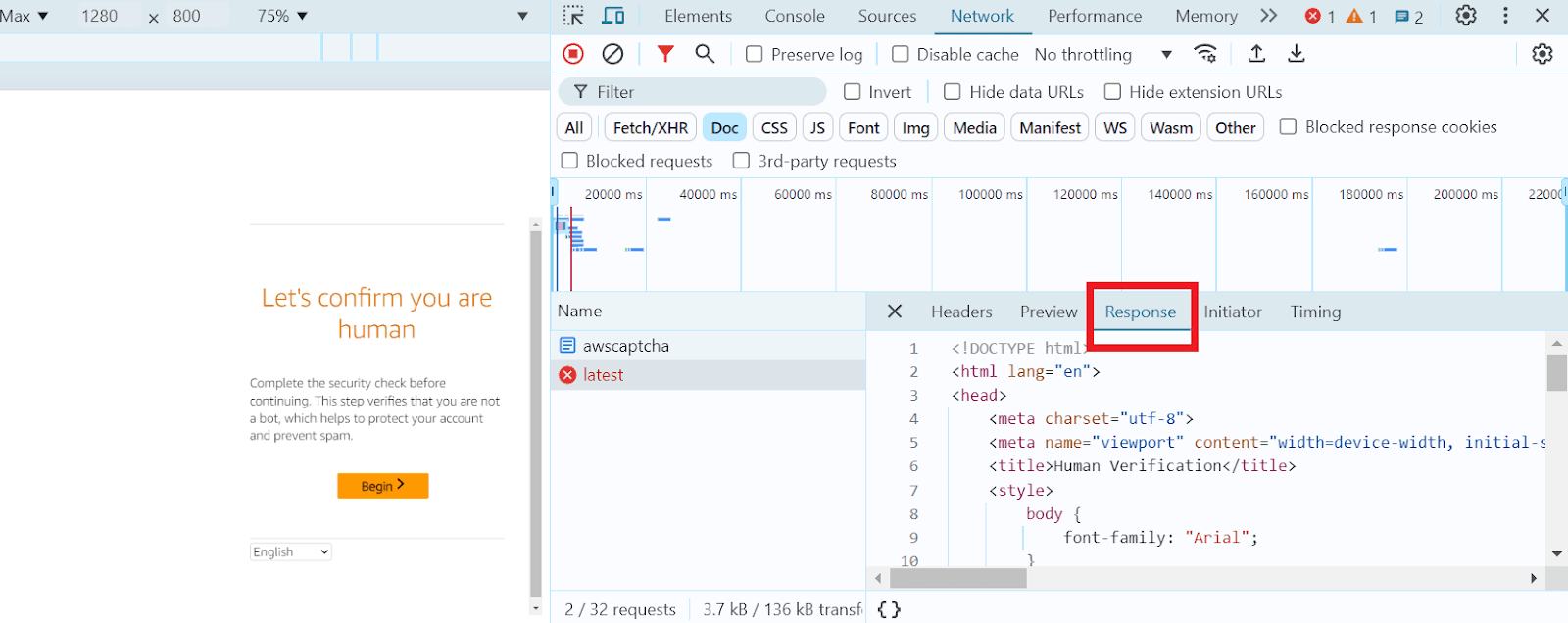
Encontre o objeto window.gokuProps, nele você encontrará todos os parâmetros necessários:
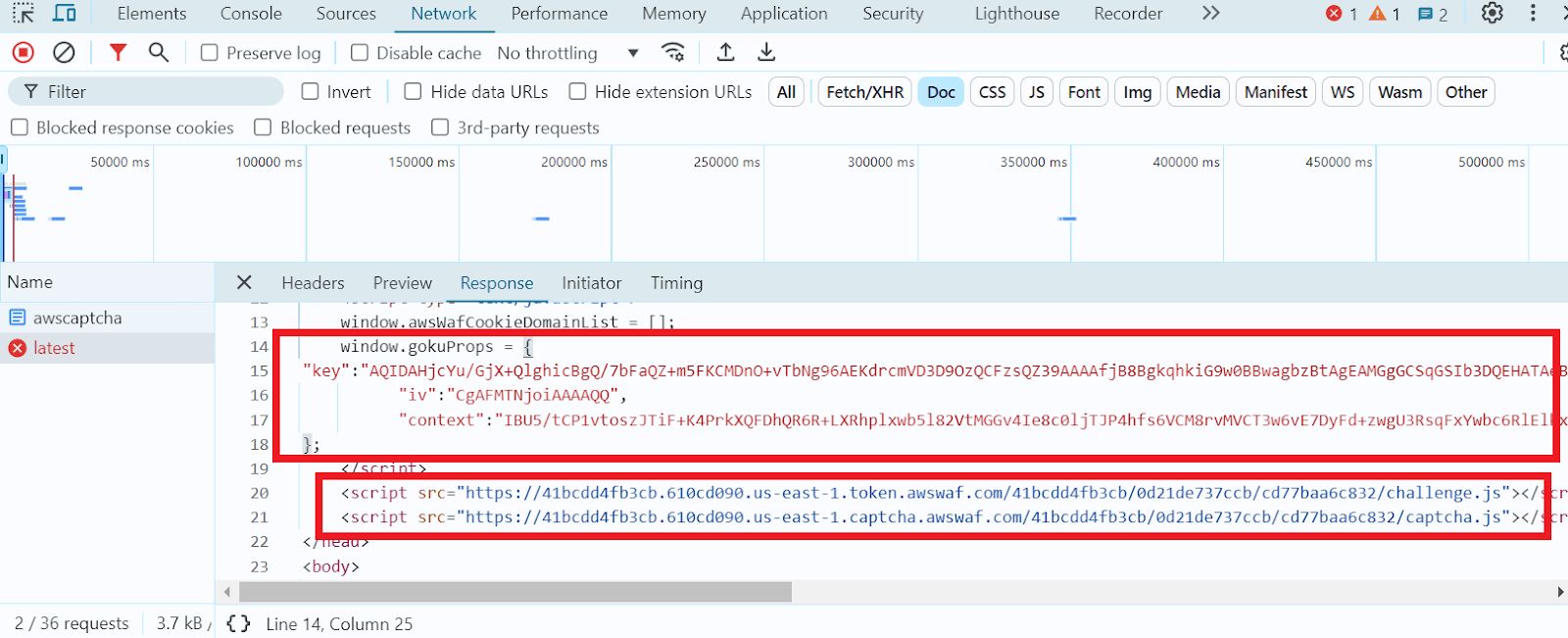
Tabela com os parâmetros necessários e seus valores
| Parâmetro | Tipo | Obrigatório | Valor |
| type | String | sim | AmazonTask |
| websiteURL | String | sim | Endereço da página principal onde a CAPTCHA é resolvida. |
| challengeScript | String | sim | Link para challenge.js |
| captchaScript | String | sim | Link para captcha.js |
| websiteKey | String | sim | String que pode ser obtida do HTML da página com CAPTCHA ou via window.gokuProps.key |
| context | String | sim | String que pode ser obtida do HTML da página com CAPTCHA ou via window.gokuProps.context |
| iv | String | sim | String que pode ser obtida do HTML da página com CAPTCHA ou via window.gokuProps.iv |
| cookieSolution | Boolean | não | Padrão false. Se forem necessários cookies aws-waf-token, defina como true. Caso contrário, você receberá captcha_voucher e existing_token. |
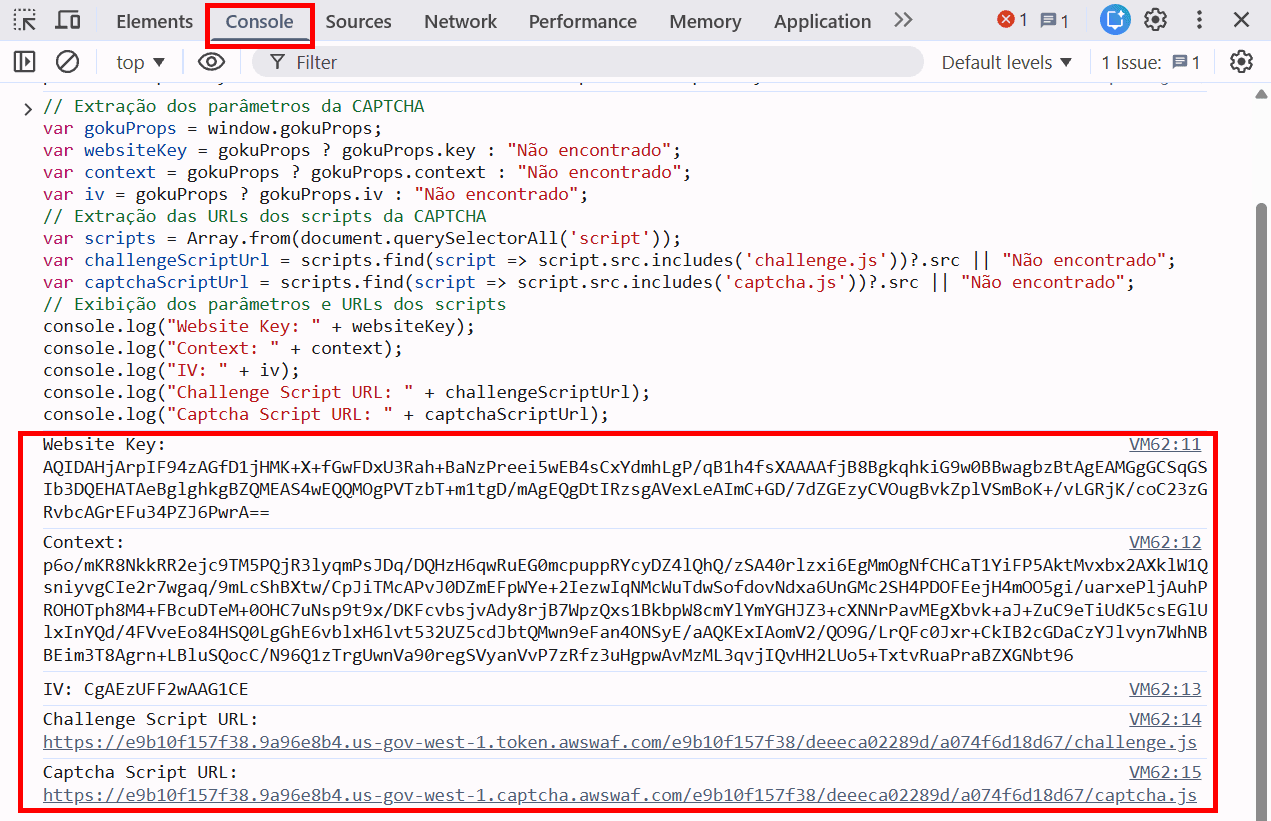
Também é possível obter automaticamente os parâmetros da CAPTCHA AWS WAF usando o seguinte código JavaScript:
// Extração dos parâmetros da CAPTCHA
var gokuProps = window.gokuProps;
var websiteKey = gokuProps ? gokuProps.key : "Não encontrado";
var context = gokuProps ? gokuProps.context : "Não encontrado";
var iv = gokuProps ? gokuProps.iv : "Não encontrado";
// Extração das URLs dos scripts da CAPTCHA
var scripts = Array.from(document.querySelectorAll('script'));
var challengeScriptUrl = scripts.find(script => script.src.includes('challenge.js'))?.src || "Não encontrado";
var captchaScriptUrl = scripts.find(script => script.src.includes('captcha.js'))?.src || "Não encontrado";
// Exibição dos parâmetros e URLs dos scripts
console.log("Website Key: " + websiteKey);
console.log("Context: " + context);
console.log("IV: " + iv);
console.log("Challenge Script URL: " + challengeScriptUrl);
console.log("Captcha Script URL: " + captchaScriptUrl);
Criação de requisição, envio da tarefa para o servidor, obtenção do resultado
Quando você já conhece todos os parâmetros da CAPTCHA, é possível criar uma tarefa para enviá-la ao servidor CapMonster Cloud.
Exemplo de requisição:
Endereço para envio: https://api.capmonster.cloud/createTask
Formato da requisição: JSON POST
{
"clientKey": "API_KEY",
"task": {
"type": "AmazonTask",
"websiteURL": "https://example.com",
"challengeScript": "https://41bcdd4fb3cb.610cd090.us-east-1.token.awswaf.com/41bcdd4fb3cb/0d21de737ccb/cd77baa6c832/challenge.js",
"captchaScript": "https://41bcdd4fb3cb.610cd090.us-east-1.captcha.awswaf.com/41bcdd4fb3cb/0d21de737ccb/cd77baa6c832/captcha.js",
"websiteKey": "AQIDA...wZwdADFLWk7XOA==",
"context": "qoJYgnKsc...aormh/dYYK+Y=",
"iv": "CgAAXFFFFSAAABVk",
"cookieSolution": true
}
}
Exemplo de resposta:
{
"errorId": 0,
"taskId": 407533072
}
Obtenção do resultado:
Use o método getTaskResult, para obter a solução da AmazonTask
https://api.capmonster.cloud/getTaskResult
Exemplo de resposta:
{
"errorId": 0,
"status": "ready",
"solution": {
"cookies": {
"aws-waf-token": "10115f5b-ebd8-45c7-851e-cfd4f6a82e3e:EAoAua1QezAhAAAA:dp7sp2rXIRcnJcmpWOC1vIu+yq/A3EbR6b6K7c67P49usNF1f1bt/Af5pNcZ7TKZlW+jIZ7QfNs8zjjqiu8C9XQq50Pmv2DxUlyFtfPZkGwk0d27Ocznk18/IOOa49Rydx+/XkGA7xoGLNaUelzNX34PlyXjoOtL0rzYBxMAQy0D1tn+Q5u97kJBjs5Mytqu9tXPIPCTSn4dfXv5llSkv9pxBEnnhwz6HEdmdJMdfur+YRW1MgCX7i3L2Y0/CNL8kd8CEhTMzwyoXekrzBM="
},
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/147.0.0.0 Safari/537.36"
}
}
Exemplo de código para resolver CAPTCHA da Amazon durante web scraping em Python:
Durante o web scraping podem surgir diversos obstáculos, como a interrupção do script devido ao aparecimento de um CAPTCHA da Amazon no site de destino. Para contornar esse problema, você pode adicionar ao seu scraper um código adicional para resolução automática do CAPTCHA, que aguardará o frame do CAPTCHA, extrairá todos os parâmetros necessários e enviará a solução para o servidor CapMonster Cloud.
Como isso pode ser implementado: suponha que exista um script de scraping de um site de clima em Python usando Selenium:
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
try:
# Abertura da página principal de clima
driver.get('https://example.com')
# Busca do campo de entrada de cidade, inserção do nome da cidade
search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "header-location-search")) # Substitua pelo valor necessário
)
search_box.send_keys("Moscow") # Substitua pelo valor necessário
search_box.send_keys(Keys.RETURN)
# Aguarda o carregamento da página de resultados
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.locations-list') )# Substitua pelo valor necessário
)
# Seleciona e clica no primeiro resultado
first_result = driver.find_element(By.CSS_SELECTOR, 'div.locations-list a') # Substitua pelo valor necessário
first_result.click()
E nessa mesma página é necessário resolver o CAPTCHA da Amazon. Adicione o código para resolução do CAPTCHA:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import requests
import time
# API_KEY do CapMonster Cloud
API_KEY = os.getenv('CAPMONSTER_API_KEY')
CREATE_TASK_URL = 'https://api.capmonster.cloud/createTask'
GET_TASK_RESULT_URL = 'https://api.capmonster.cloud/getTaskResult'
def create_task(website_key, context, iv, challenge_script_url, captcha_script_url):
print("Criando tarefa...")
task_data = {
"clientKey": API_KEY,
"task": {
"type": "AmazonTask",
"websiteURL": 'https://example.com', # Substitua pelo valor necessário
"challengeScript": challenge_script_url,
"captchaScript": captcha_script_url,
"websiteKey": website_key,
"context": context,
"iv": iv,
"cookieSolution": False # Defina como True se precisar de cookies "aws-waf-token"
}
}
response = requests.post(CREATE_TASK_URL, json=task_data)
response_json = response.json()
if response_json['errorId'] == 0:
print(f"Tarefa criada com sucesso. Task ID: {response_json['taskId']}")
return response_json['taskId']
else:
print(f"Erro ao criar tarefa: {response_json['errorCode']}")
return None
def get_task_result(task_id):
print("Obtendo resultado da tarefa...")
result_data = {"clientKey": API_KEY, "taskId": task_id}
while True:
response = requests.post(GET_TASK_RESULT_URL, json=result_data)
response_json = response.json()
if response_json['status'] == 'ready':
print(f"Resultado da tarefa pronto: {response_json}")
return response_json
elif response_json['status'] == 'processing':
print("A tarefa ainda está sendo processada...")
time.sleep(5)
else:
print(f"Erro ao obter resultado da tarefa: {response_json['errorCode']}")
return response_json
# Inicialização do navegador
driver = webdriver.Chrome()
try:
# Abertura da página principal
print("Abrindo a página...")
driver.get('https://example.com')
# Inserção da cidade para busca
search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "header-location-search"))
)
search_box.send_keys("Moscow") # Substitua pela sua cidade
search_box.send_keys(Keys.RETURN)
# Aguarda o aparecimento do CAPTCHA
print("Aguardando iframe...")
iframe = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'iframe[src*="execute-api"]'))
)
driver.switch_to.frame(iframe)
print("Aguardando CAPTCHA, extraindo parâmetros...")
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#captcha-container'))
)
goku_props = driver.execute_script("return window.gokuProps;")
website_key = goku_props["key"]
context = goku_props["context"]
iv = goku_props["iv"]
challenge_script_url, captcha_script_url = [
driver.execute_script(f"return document.querySelector('script[src*=\"{x}\"]').src;")
for x in ("challenge.js", "captcha.js")
]
# Criação e resolução da tarefa CAPTCHA
task_id = create_task(website_key, context, iv, challenge_script_url, captcha_script_url)
if task_id:
result = get_task_result(task_id)
# Use o resultado para enviar a solução do CAPTCHA à página, se necessário
# Após resolver o CAPTCHA, continue o scraping
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.locations-list')) # Substitua pelo valor necessário
)
first_result = driver.find_element(By.CSS_SELECTOR, 'div.locations-list a') # Substitua pelo valor necessário
first_result.click()
# Demais ações
finally:
print("Fechando o navegador...")
driver.quit()
Explicação mais detalhada do código atualizado:
Importação adicional de bibliotecas requests (permite enviar requisições HTTP para interagir com a API do CapMonster Cloud) e time (usada para pausar a execução do código por um determinado tempo):
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import requests
import timeDefinição de variáveis que contêm a chave API para autenticação e os URLs para criação de tarefas e obtenção de resultados do CapMonster Cloud:
API_KEY = os.getenv('CAPMONSTER_API_KEY')
CREATE_TASK_URL = 'https://api.capmonster.cloud/createTask'
GET_TASK_RESULT_URL = 'https://api.capmonster.cloud/getTaskResult'Adição da função que cria uma tarefa para resolução de CAPTCHA e envia os dados para o servidor CapMonster Cloud. Se a tarefa for criada com sucesso, ela retorna o taskId:
def create_task(website_key, context, iv, challenge_script_url, captcha_script_url):
# ... código da funçãoAdição da função para enviar uma requisição POST para verificar o status da tarefa. Se o status for 'ready', a função retorna o resultado; caso contrário, aguarda e verifica novamente:
def get_task_result(task_id):
# ... código da funçãoApós inicializar o navegador e abrir a página alvo (neste caso https://example.com como exemplo), aguarda-se o campo de busca, insere-se o nome da cidade e envia o formulário:
search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "header-location-search"))
)
search_box.send_keys("Moscow")
search_box.send_keys(Keys.RETURN)Em seguida, aguarda-se o aparecimento do iframe do CAPTCHA, alterna-se para ele e extrai-se os parâmetros necessários para a resolução:
iframe = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'iframe[src*="execute-api"]'))
)
driver.switch_to.frame(iframe)
—-----
goku_props = driver.execute_script("return window.gokuProps;")
website_key = goku_props["key"]
context = goku_props["context"]
iv = goku_props["iv"]
challenge_script_url, captcha_script_url = [
driver.execute_script(f"return document.querySelector('script[src*=\"{x}\"]').src;")
for x in ("challenge.js", "captcha.js")
]Criação da tarefa para resolução do CAPTCHA e espera pelo resultado:
task_id = create_task(website_key, context, iv, challenge_script_url, captcha_script_url)
if task_id:
result = get_task_result(task_id)Continuação do scraping:
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.locations-list'))
)
first_result = driver.find_element(By.CSS_SELECTOR, 'div.locations-list a')
first_result.click()
# Demais ações ...Dicas e recomendações
O código descrito acima é apresentado como um exemplo e demonstra a lógica geral de execução das ações. Todas as ações e nomes de elementos dependem do site específico e de sua estrutura. Você precisará estudar o código HTML do site, bem como se familiarizar com a documentação das ferramentas que pretende usar para web scraping. Cada site é único, e para um scraping bem-sucedido pode ser necessário adaptar o código e as abordagens de acordo com as características do recurso alvo. Além disso, o trabalho com CAPTCHA da Amazon possui suas próprias particularidades que devem ser levadas em consideração.
Aqui estão algumas dicas gerais úteis para um web scraping bem-sucedido e para lidar com o CAPTCHA da Amazon (AWS WAF):
Assincronia. No nosso exemplo simples de código de scraping e bypass de CAPTCHA, não é usado método assíncrono. No entanto, se você trabalha com grandes volumes de dados ou sites com resposta lenta, é melhor usar programação assíncrona para execução paralela de tarefas e acelerar o processo.
Modo headless. Execute o navegador em modo headless para acelerar o processamento e economizar recursos. Sem interface gráfica, o processo pode ser mais eficiente.
Navegador com interface gráfica. Se o site exigir interações complexas, use um navegador com interface gráfica. Isso ajuda a lidar com elementos da interface, testar melhor seu código e evitar alguns erros e bloqueios.
Troca de IP e User-Agent. Para evitar bloqueios e restrições do site, altere regularmente o endereço IP e o User-Agent. Use proxies de qualidade e altere o User-Agent nas requisições para não levantar suspeitas de automação.
Processamento de CAPTCHAs dinâmicas. A Amazon usa CAPTCHAs que podem mudar dependendo do tempo ou da atividade, além de atualizar constantemente seus métodos de proteção contra bots. Certifique-se de que seu script se adapta a essas mudanças e lida corretamente com elas. Acompanhe atualizações e novidades dos serviços de resolução de CAPTCHA.
Redução da frequência de requisições. Não faça requisições com muita frequência para não atrair a atenção dos sistemas anti-bot da Amazon, ou distribua-as entre diferentes IPs.
Links úteis:
Documentação Selenium WebDriver
Documentação API CapMonster Cloud
Conclusão
A resolução do CAPTCHA da Amazon (AWS WAF) pode causar dificuldades significativas na coleta de dados. No entanto, conhecendo os princípios básicos de funcionamento desse sistema e utilizando as ferramentas corretas, é possível lidar com essas tarefas de forma eficiente.
Foram abordados os principais pontos, incluindo a descrição desse tipo de CAPTCHA e sua resolução com o CapMonster Cloud. As etapas mais importantes são a extração correta dos parâmetros necessários do CAPTCHA, a criação e envio da tarefa ao servidor, e a obtenção e uso da solução. Também foi apresentado um exemplo de código em Python que demonstra, de forma geral, como integrar a resolução de CAPTCHA ao processo de web scraping. O sucesso nessa área depende não apenas de habilidades técnicas, mas também da capacidade de se adaptar rapidamente a mudanças e novas técnicas de proteção contra bots.
NB: Por favor, note que o produto é destinado à automação de testes exclusivamente em seus próprios sites e recursos, aos quais você tenha direito legal de acesso.






