Scraping de sites com Python e Selenium: fundamentos e automação
Hoje, a importância da informação atingiu seu auge, e a capacidade de extrair e analisar dados de recursos da internet tornou-se extremamente importante e muito procurada. Neste artigo, vamos abordar os fundamentos do web scraping utilizando Python e Selenium, além de discutir como a tecnologia CapMonster Cloud ajuda a superar dificuldades com diferentes tipos de CAPTCHAs. Você aprenderá como essas ferramentas podem melhorar significativamente sua capacidade de obter e processar dados da internet, abrindo novos horizontes para pesquisas, análise de dados e automação de processos.
Comece agora e automatize sua solução reCAPTCHA v2
Web scraping é o processo de extração de dados de páginas da web. Esse processo geralmente envolve o uso de um programa ou scripts que coletam informações apresentadas em sites, as quais podem ser utilizadas em diversas áreas e para diferentes finalidades. Por exemplo, para comparação de preços e serviços de concorrentes, análise de preferências dos consumidores, monitoramento de notícias e eventos, entre outros.
As etapas do web scraping incluem:
Definição dos objetivos: na primeira etapa é necessário entender quais informações devem ser extraídas e de quais sites.
Análise da estrutura da página-alvo: estudo do código HTML das páginas para entender onde e como as informações estão armazenadas. Identificação de elementos como tags, IDs, classes e outros.
Desenvolvimento do script para coleta de dados: escrita de código (por exemplo, em Python com a biblioteca Selenium para automação de ações no navegador), que acessa páginas da web, extrai os dados necessários e os salva em formato estruturado.
Processamento de dados: os dados extraídos frequentemente precisam ser transformados para uso posterior. Isso pode incluir remoção de duplicatas, correção de formatos, filtragem de dados desnecessários, entre outros.
Armazenamento de dados: salvar os dados extraídos e processados em um formato conveniente, como CSV, JSON, banco de dados, entre outros.
Também é importante acompanhar as mudanças no site-alvo para atualizar o script sempre que necessário.
Trabalhando com Python e Selenium
Por que Python e Selenium são convenientes para web scraping?
A linguagem de programação Python e a biblioteca Selenium são frequentemente usadas para web scraping pelos seguintes motivos:
Facilidade de uso: Python é simples de usar e possui muitas bibliotecas para web scraping.
Emulação de ações e acesso a conteúdo dinâmico: com o Selenium é possível automatizar ações do usuário no navegador, incluindo rolagem de página e cliques necessários para carregar dados.
Contorno de anti-crawlers: alguns sites utilizam mecanismos de proteção especiais, e a simulação de ações de um usuário real ajuda a contornar essas proteções.
Amplo suporte: uma grande comunidade e muitos recursos facilitam o uso dessas ferramentas.
Se o Python ainda não estiver instalado no seu computador, acesse o site oficial do Python e baixe a versão adequada para o seu sistema operacional (Windows, macOS, Linux). No terminal do seu ambiente de desenvolvimento, você pode verificar a versão do Python com o seguinte comando:
python --version
Em seguida, é necessário instalar o Selenium executando o comando:
pip install selenium
Crie um novo arquivo e importe as bibliotecas necessárias:
import time
from selenium import webdriver
Também é necessário adicionar ao projeto a classe “By”, que será usada para definir estratégias de localização de elementos na página com Selenium:
from selenium.webdriver.common.by import By
Parâmetros do driver do Chrome
As opções do ChromeDriver (ChromeOptions) são usadas para configurar o comportamento e os parâmetros de inicialização do navegador Chrome durante a automação com Selenium. Aqui estão algumas dessas opções:
--headless: inicia o Chrome sem interface gráfica
--disable-gpu: desativa o uso da GPU. Frequentemente usado com --headless para evitar erros relacionados à renderização gráfica
--disable-popup-blocking: desativa o bloqueio de janelas pop-up
--disable-extensions: desativa todas as extensões do navegador
--incognito: inicia o navegador em modo anônimo, que não salva histórico, cookies e outros dados de sessão
--window-size=width,height: define o tamanho da janela do navegador
--user-agent=<user-agent>: define um user-agent personalizado para simular diferentes dispositivos ou navegadores
A lista completa de parâmetros pode ser vista aqui.
No nosso exemplo, o modo anônimo está ativado. Inicialize o driver do Chrome e acesse a página do produto:
No Selenium, a busca de elementos em uma página web é realizada por meio de diferentes métodos fornecidos pela classe By. Esses métodos permitem localizar elementos por diversos critérios, como identificador do elemento (ID), nome da classe (class name), nome da tag (tag name), nome do atributo (name), texto do link (link text), XPath ou seletor CSS.
Exemplo de busca por ID:
element = driver.find_element(By.ID, 'element_id')
Por nome da classe:
element = driver.find_element(By.CLASS_NAME, 'class_name')
Por nome da tag:
element = driver.find_element(By.TAG_NAME, 'tag_name')
Por nome do atributo:
element = driver.find_element(By.NAME, 'element_name')
Por texto do link:
element = driver.find_element(By.LINK_TEXT, 'link_text')
Por seletor CSS:
element = driver.find_element(By.CSS_SELECTOR, 'css_selector')
Por XPath:
element = driver.find_element(By.XPATH, '//tag[@attribute="value"]')
Se for necessário encontrar vários elementos, em vez de find_element usa-se o método find_elements.
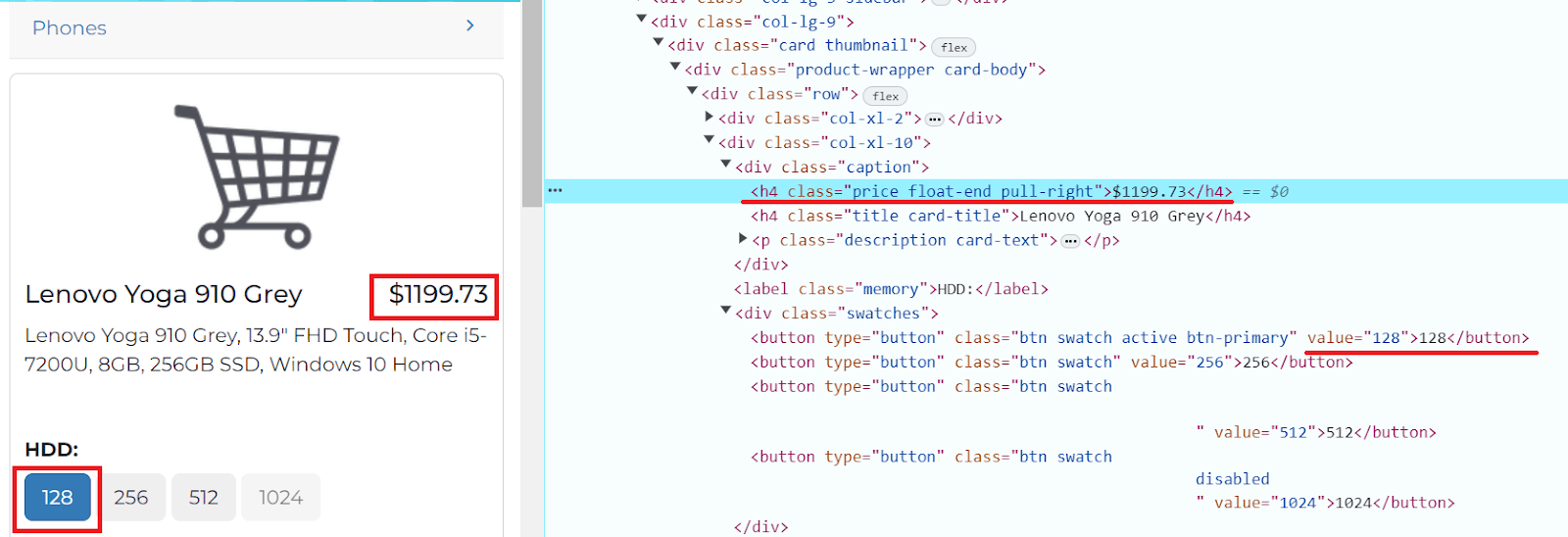
No nosso exemplo, é necessário encontrar a localização do elemento do botão “128” e as informações de preço:
Simulação de ações do usuário
No Selenium, a simulação de ações na página web é feita por meio de métodos fornecidos pelo objeto WebElement. Esses métodos permitem interagir com os elementos da página como um usuário real: clicar, inserir texto etc.
Aqui estão alguns desses métodos:
element.click() - clique no elemento
element.send_keys('texto para inserção') - inserção de texto no elemento (campo de entrada)
element.location_once_scrolled_into_view - rolagem até o elemento
submit() - envio do formulário
Voltando ao nosso exemplo. Usando XPath, é feita a busca do botão desejado, depois é necessário clicar nele e encontrar o elemento com o preço:
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
# Aguardando alguns segundos para o carregamento do preço
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
Agora resta exibir o preço do produto com o volume de HDD desejado no console:
price_text = price_element.text
print("Preço do produto:", price_text)
driver.quit()
Assim, eis como fica o código completo:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
price_text = price_element.text
print("Preço do produto:", price_text)
driver.quit()
Banners e janelas pop-up
Muito frequentemente, sites exibem vários banners e janelas pop-up, que podem interferir na execução do script. Nesses casos, é possível configurar os parâmetros do ChromeDriver para desativar esses elementos. Aqui estão alguns desses parâmetros:
--disable-popup-blocking: desativa o bloqueio de janelas pop-up
--disable-infobars: desativa barras de informação
--disable-notifications: desativa todas as notificações
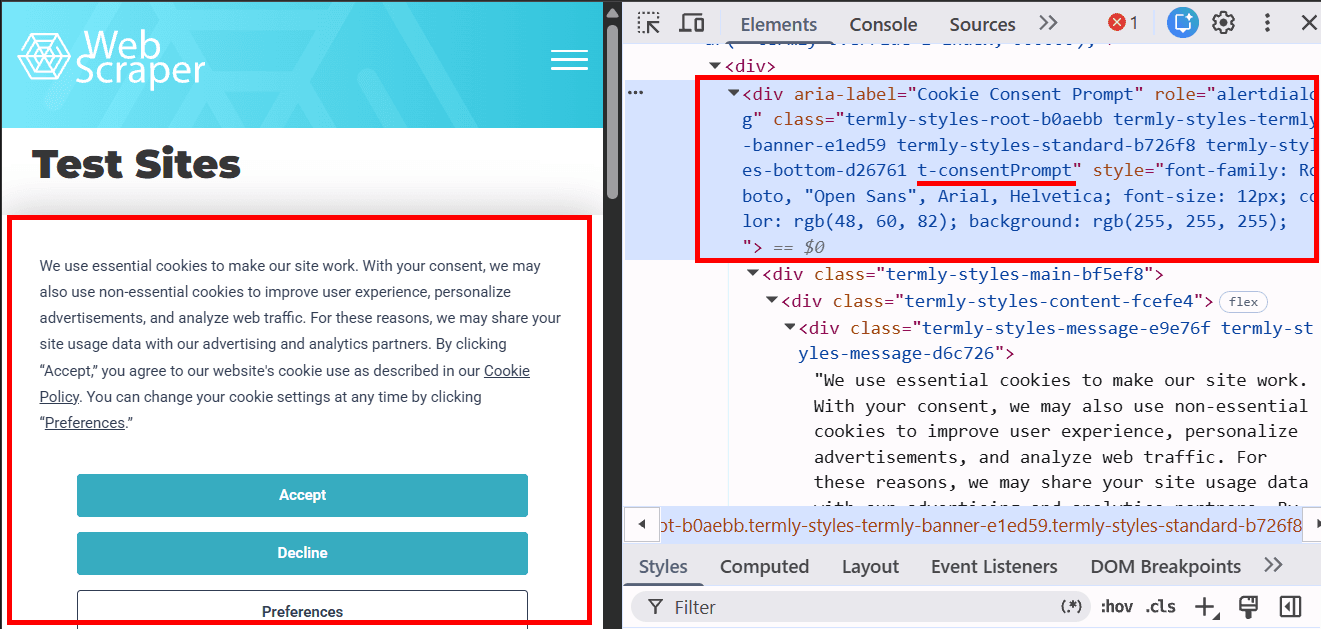
No site que usamos no nosso exemplo, ao carregar a página aparece um banner de cookies. Também é possível removê-lo de outras formas, uma delas é usando um script separado que bloqueia essas notificações. Primeiro, vamos analisar esse elemento com as Ferramentas de Desenvolvedor:
Usaremos a classe .t-consentPrompt para encontrar o banner de cookies, porque esse é o elemento mais estável e legível em CSS. Classes geradas automaticamente, como termly-styles-root-b0aebb, podem mudar após atualizações do site, por isso geralmente não são usadas em automação.
O banner será ocultado via style.display = 'none', para que não cubra a página e não interfira na interação do Selenium com os elementos do site.
Agora podemos ocultar esse banner adicionando a lógica correspondente ao nosso script:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
# Script para ocultar o banner de cookies da Termly
script = """
var banner = document.querySelector('.t-consentPrompt');
if (banner) {
banner.style.display = 'none';
}
"""
driver.execute_script(script)
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
price_text = price_element.text
print("Preço do produto:", price_text)
driver.quit()
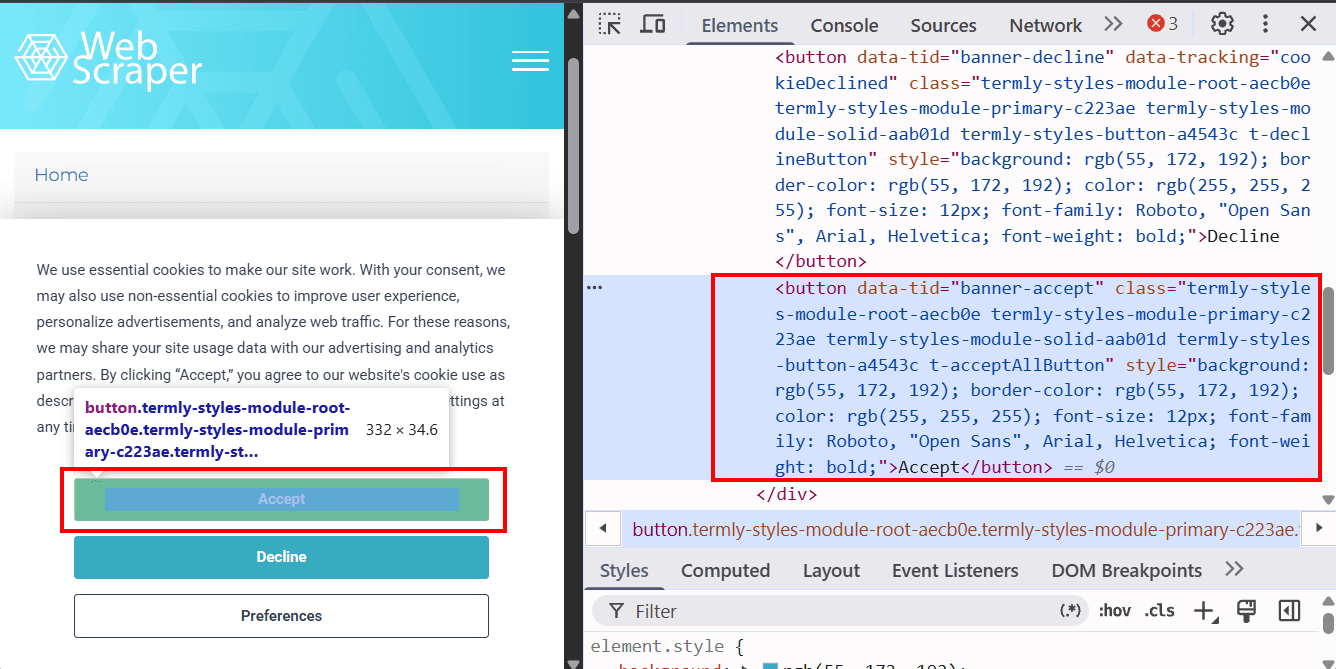
Outro método para fechar o banner é simular a ação do usuário clicando nos botões Accept ou Decline. Analise o elemento necessário (por exemplo, o botão Accept):
Podemos encontrar o botão pelo atributo data-tid="banner-accept" e clicar nele usando button.click():
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
# Aguarde o botão Accept e clique nele
accept_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(
(By.XPATH, "//button[@data-tid='banner-accept']")
)
)
accept_button.click()
# Clique no botão 128 GB
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
# Obtenção do preço
price_element = driver.find_element(
By.XPATH,
"//h4[@class='price float-end pull-right']"
)
price_text = price_element.text
print("Preço do produto:", price_text)
driver.quit()
Outro método eficaz é usar extensões do Chrome que aceitam ou bloqueiam automaticamente todos os banners de cookies. Essas extensões podem ser instaladas no navegador e adicionadas ao ChromeOptions. Baixe uma extensão adequada no formato .crx e use-a no seu script:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# Caminho para a extensão .crx
extension_path = '/path/to/extension.crx'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
# Adicionando a extensão
chrome_options.add_extension(extension_path)
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
price_text = price_element.text
print("Preço do produto:", price_text)
driver.quit()
Essa abordagem elimina a necessidade de interagir manualmente com esses elementos ao carregar a página.
Resolução de CAPTCHA no web scraping
Muitas vezes, ao extrair dados, surgem obstáculos na forma de CAPTCHAs, projetados para proteger contra bots. Para contornar essas restrições, são mais eficazes serviços especializados que reconhecem diferentes tipos de CAPTCHA. Uma dessas ferramentas é o CapMonster Cloud, que é capaz de resolver automaticamente até os CAPTCHAs mais complexos em poucos segundos. Este serviço oferece tanto extensões de navegador (para Chrome, paraFirefox), quanto métodos de API (que podem ser consultados na documentação), que você pode integrar ao seu código para obter tokens, contornar a proteção com sucesso e continuar a execução do seu script.
Alguns tipos de CAPTCHA que o CapMonster Cloud resolve com facilidade:
Todos os tipos de reCAPTCHA
GeeTest
Cloudflare Turnstile e Challenge
DataDome
Exemplo de código para resolução automática de CAPTCHA e web scraping
Este script utiliza a biblioteca oficial Python do CapMonster Cloud e o Selenium para resolver o CAPTCHA na página, após o que extrai o título dessa página e o imprime no console:
import asyncio
from selenium import webdriver
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from capmonstercloudclient import CapMonsterClient, ClientOptions
from capmonstercloudclient.requests import RecaptchaV2Request
async def solve_captcha(api_key, page_url, site_key):
client_options = ClientOptions(api_key=api_key)
cap_monster_client = CapMonsterClient(options=client_options)
recaptcha2request = RecaptchaV2Request(websiteUrl=page_url, websiteKey=site_key)
responses = await cap_monster_client.solve_captcha(recaptcha2request)
return responses['gRecaptchaResponse']
async def parse_site_title(driver: WebDriver, url: str) -> str:
driver.get(url)
driver.implicitly_wait(10)
title_element = driver.find_element(By.TAG_NAME, 'title')
title = title_element.get_attribute('textContent')
return title
async def main():
api_key = 'YOUR_API_KEY' # Substitua pela sua chave de API do CapMonsterCloud
page_url = 'https://lessons.zennolab.com/captchas/recaptcha/v2_simple.php?level=low'
site_key = '6Lcf7CMUAAAAAKzapHq7Hu32FmtLHipEUWDFAQPY'
options = Options()
driver = webdriver.Chrome(options=options)
captcha_response = await solve_captcha(api_key, page_url, site_key)
print("Solução da captcha:", captcha_response)
site_title = await parse_site_title(driver, page_url)
print("Título da página:", site_title)
driver.quit()
if __name__ == "__main__":
asyncio.run(main())
Conclusão
O uso de Python e Selenium para web scraping abre inúmeras possibilidades para automação da coleta de dados de sites, e a integração com o CapMonster Cloud ajuda a contornar facilmente CAPTCHAs e simplifica significativamente o processo de coleta de informações. Essas ferramentas permitem não apenas acelerar o trabalho, mas também garantir a precisão e a confiabilidade dos dados obtidos. Com elas, você pode coletar dados de diversas fontes, desde lojas online até sites de notícias, e utilizá-los para análise, pesquisa ou criação de seus próprios projetos. Além disso, não é necessário ter conhecimentos avançados de programação — as tecnologias modernas tornam o web scraping acessível até para iniciantes. Portanto, se para você são importantes simplicidade, conveniência máxima e economia de tempo no trabalho com dados, Python, Selenium e CapMonster Cloud são uma excelente combinação para alcançar esse objetivo!
NB: Por favor, observe que o produto é destinado à automação de testes exclusivamente em seus próprios sites e em recursos para os quais você possui autorização legal de acesso.
As 10 melhores ferramentas de web scraping para extrair conteúdo de vários sites ao mesmo tempo
Compare as 10 melhores ferramentas de web scraping para extração de dados de vários sites em 2026. Prós, contras, preços e como escolher a ferramenta certa para sua pilha.