
As 10 melhores ferramentas de web scraping para extrair conteúdo de vários sites ao mesmo tempo
No último trimestre, nossa equipe tentou extrair dados de produtos de 38 sites de comércio eletrônico de nicho para uma análise de mercado. O raspador que construímos para o primeiro local aguentou cerca de três. No local sete, já estava quebrado em quatro locais diferentes.
Essa é a lacuna que este guia preenche. Escolher as ferramentas certas de web scraping quando você faz scraping de muitos sites ao mesmo tempo é um problema completamente diferente de extrair dados de um único site. Um site você consegue ajustar. Quarenta sites com layouts diferentes, pilhas anti-bot diferentes e fluxos de login diferentes vão derrubar qualquer ferramenta que não foi feita para isso.
Testamos e comparamos 10 das melhores ferramentas de web scraping disponíveis em 2026, desde extensões do Chrome com tecnologia de IA até APIs de scraping de nível empresarial, e as classificamos de acordo com seu desempenho em muitos sites. Você obterá prós e contras honestos, preços atuais e uma noção clara de qual web scraper se adapta ao seu caso de uso.
Por que o web scraping em vários sites é mais complicado do que a extração de uma única página?
O web scraping em vários sites é mais difícil porque cada site é seu próprio microprojeto. Diferentes estruturas HTML, diferentes padrões de paginação, diferentes pilhas anti-bot e diferentes paredes de login aumentam rapidamente quando você atinge dezenas de alvos em um pipeline.
Três coisas tornam isso difícil na prática:
- Variação de layout.Um seletor que funciona no Site A quebra no Site B. Quanto mais sites no escopo, mais quebras.
- Diversidade anti-bot.Um site usa Cloudflare Turnstile, outro DataDome e um terceiro reCAPTCHA Enterprise. Cada um tem seu próprio fluxo de desafio.
- Limites de volume e taxa.Em muitos sites, você aciona limites de taxas, impressões digitais e verificações comportamentais com mais frequência do que um scraper de alvo único faria.
A escala do tráfego automatizado mostra como os sites de alerta se tornaram. De acordo com o 2025 Imperva Bad Bot Report, o tráfego automatizado ultrapassou o tráfego gerado por humanos pela primeira vez em uma década, constituindo 51% de todo o tráfego da web em 2024. O mesmo relatório observa que a Imperva bloqueou 13 trilhões de solicitações ruins de bots em milhares de domínios no ano passado. Cada site que você raspa está em guarda.
Entretanto, a procura por estes dados continua a crescer. Mordor Intelligencedescobriram que 65% das empresas usaram web scraping para alimentar projetos de IA e aprendizado de máquina em 2024. As guerras de preços em tempo real levaram 81% dos varejistas dos EUA a adotarem a raspagem automatizada de preços para reavaliação dinâmica de preços, acima dos 34% em 2020.
As equipes que dimensionam a coleta de dados vencem. Aqueles que não podem perder terreno. A ferramenta certa decide em qual grupo você entra.
O que você deve procurar em ferramentas de web scraping que extraem conteúdo de vários sites?
As melhores ferramentas de web scraping que extraem conteúdo de vários sites compartilham cinco características: flexibilidade de layout, manipulação de paginação, resiliência anti-bot, saída estruturada limpa e tarefas reutilizáveis. Perca qualquer um deles e você gastará mais tempo consertando raspadores quebrados do que analisando dados.
Aqui está a lista de verificação prática que usamos para classificar as ferramentas abaixo.
Algumas coisas não óbvias que vale a pena sinalizar:
- Código ou no-codeé uma bifurcação real.Scrapers visuais como Octoparse ou ParseHub economizam semanas de configuração, mas atingem o limite em sites altamente dinâmicos. Estruturas baseadas em código, como Scrapy ou Playwright, lidam com qualquer coisa, mas exigem tempo de engenharia.
- A IA mudou o cenário.Os scrapers modernos de IA leem uma página semanticamente. Eles entendem o que significa “preço” ou “avaliação” sem um seletor codificado, que generaliza entre sites de uma forma que os scrapers baseados em modelos não conseguem.
- CAPTCHAs são um item de linha inevitável.Quanto mais sites você acessar, mais CAPTCHAs verá. Planeje isso antecipadamente com um solucionador dedicado, em vez de aplicá-lo após o início do pipeline.
falhando.
Quais são as 10 melhores ferramentas de web scraping para dados de vários sites em 2026?
As 10 melhores ferramentas de web scraping para extração de dados de vários sites em 2026 são Chat4Data, Octoparse, Apify, Bright Data, ScrapingBee, Browse.ai, ParseHub, Zyte, Scrapy e Playwright. Cada um se adapta a uma combinação diferente de escala, conforto técnico e orçamento.
Aqui está a tabela resumida antes de começarmos.
Agora as entradas.
1. Chat4Data: raspagem com IA em linguagem natural em vários sites
Chat4Dataé um raspador web com IAque funciona como uma extensão do Chrome. Abra qualquer página da web pública, digite o que deseja em linguagem natural (“obtenha o nome do produto, marca, classificação, contagem de avaliações e preço para os 50 principais resultados de Lego na Amazon”) e o agente mostrará um passo a passo plano antes de executá-lo. Revise o plano, clique em start e os dados serão exportados para Excel, CSV ou JSON.
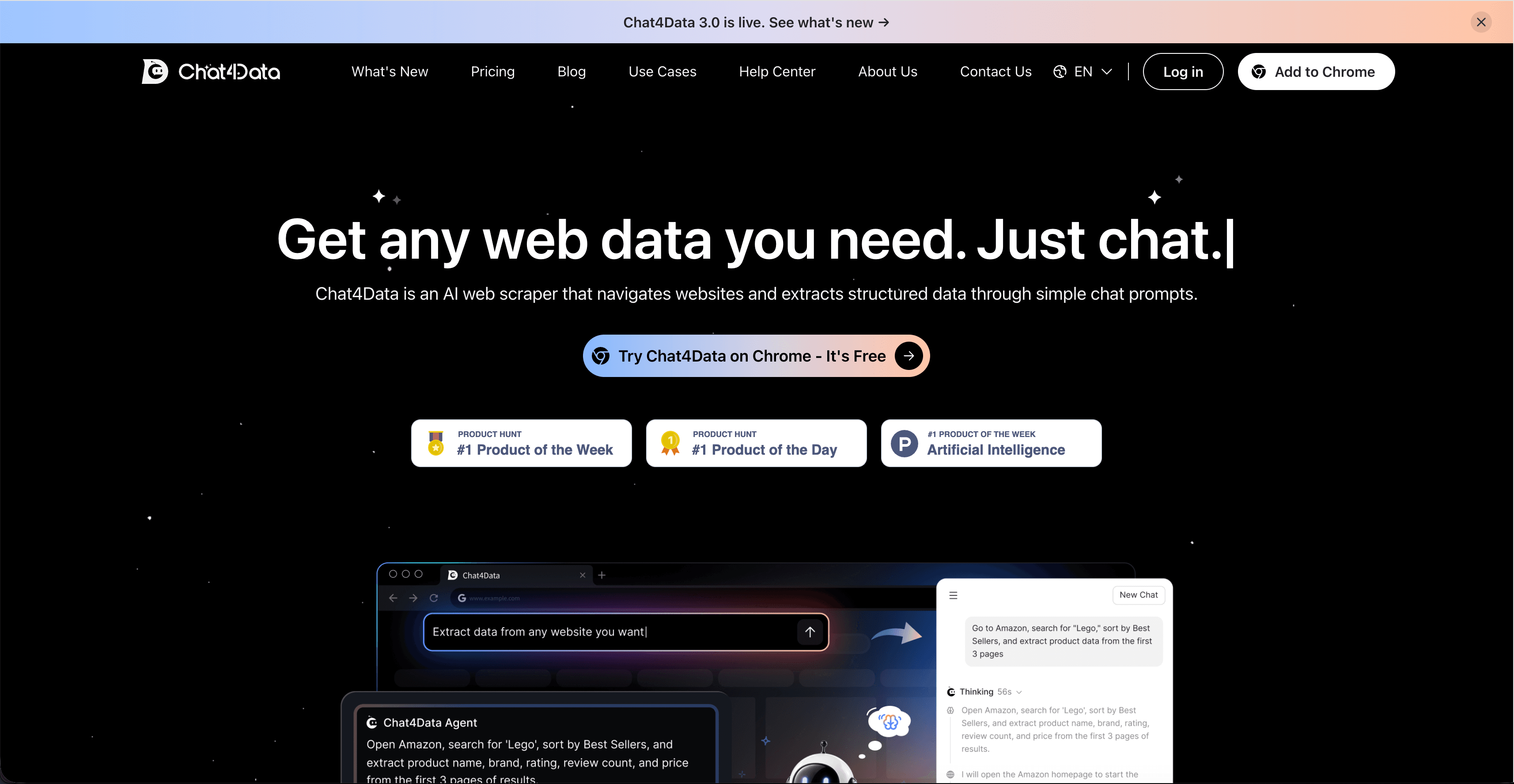
O que faz o Chat4Data se adequar ao caso de uso de vários sites é que a mesma interface em linguagem natural funciona independentemente do layout do site. Não há modelos por site para manter. Em um diretório imobiliário, peça o address, price, beds, and agent contact. Em um site de comparação de SaaS, peça the vendor name, pricing tier, and key features. Mesmo fluxo de trabalho, sites diferentes.
Na minha primeira tentativa, explorando um site de comparação de SaaS, pedi pricing tier, key features, and vendor name. O agente agarrou o nível de preços e o fornecedor de forma clara, mas perdeu dois recursos que viviam dentro de um acordeão em colapso. Ajustei o prompt para adicionar “incluindo recursos ocultos nos botões ‘Mostrar mais’”e correu novamente. Segunda passagem, concluída. A visualização do plano foi o que facilitou a correção: pude ver exatamente quais etapas o agente estava pulando.
Tipo:Agente de web scraping de IA (extensão do Chrome).
Ideal para:Usuários não técnicos, incluindo vendedores, profissionais de marketing e pesquisadores, que precisam de dados limpos de diversas páginas públicas sem escrever código.
Principais recursos:
- Prompts em linguagem natural, sem seletores ou modelos;
- Extração de página inteira em uma tarefa (título, preço, especificações, comentários juntos);
- Pré-visualização do planejamento antes da execução para ver o que o agente fará;
- Pausa para logins e CAPTCHAs e depois retoma;
- Paginação, rolagem infinita e manipulação de páginas de detalhes são automáticas;
- Configure uma vez, execute novamente mais tarde. Repetir raspagens não consome créditos;
- Exporta para Excel, CSV, JSON.
Vantagens:Caminho mais rápido da ideia aos dados para não programadores. O mesmo fluxo de trabalho lida com sites totalmente diferentes. Escopo honesto: desenvolvido para lotes de até dezenas de milhares de registros, que abrange a maioria dos trabalhos reais de geração de leads, e-commerce e pesquisa.
Desvantagens:A configuração inicial da IA consome créditos em cada nova página. É executado na guia ativa do Chrome, portanto, pipelines industriais muito grandes que extraem milhões de registros pertencem a uma pilha diferente.
Preços:Plano gratuito com 300 créditos de boas-vindas; Pro, US$ 10/mês com 2.000 créditos mensais; Máximo, US$ 35/mês com 8.000 créditos. O faturamento anual economiza 30%. Você pode obter o Chat4Data na Chrome Web Store.
2. Octoparse: modelos que se espalham por sites semelhantes
Octoparse é um visual no-code web scraping toolcom mais de 600 modelos pré-construídos para sites populares e um recurso de detecção automática de IA que cria um scraper funcional em menos de 30 segundos na maioria das páginas padrão. É a escolha certa quando você coleta o mesmo tipo de dados em muitos sites semelhantes: dez mercados imobiliários diferentes ou quinze lojas de comércio eletrônico de nicho com layouts comparáveis.
Fiquei surpreso com o quanto a detecção automática de trabalho pesado funcionou na primeira tentativa. Em uma página de categoria de comércio eletrônico de 48 produtos, ele selecionou os campos corretos (nome, preço, classificação, URL) na primeira passagem e administrou a paginação sem que eu tocasse em nada. Octoparse se destaca em trabalhos recorrentes em vários locais porque os modelos são reutilizáveis e a versão em nuvem funciona 24 horas por dia com rotação de IP integrada. Um raspador que você cria para o Site A pode ser clonado e editado para o Site B em minutos quando os layouts são semelhantes.
Tipo: Raspador visual no-code (desktop + cloud).
Ideal para:Extração recorrente de dados em muitos sites com layouts semelhantes (comércio eletrônico, imóveis, quadros de empregos, diretórios).
Principais recursos:
- Mais de 600 modelos pré-construídos cobrindo sites comuns;
- A detecção automática de IA cria scrapers sem seleção manual de campo;
- Agendamento de nuvem, rotação de IP, resolução de CAPTCHA;
- Execuções simultâneas de nuvem para raspagem paralela;
- Exporte para Excel, CSV, JSON, Planilhas Google e bancos de dados.
Vantagens:Maduro, estável, usado por mais de 3 milhões de pessoas. O plano gratuito é generoso (10 tarefas, 50 mil registros/mês). Os modelos reduzem drasticamente o tempo de configuração.
Desvantagens:Luta com sites muito dinâmicos e com muito JavaScript. Os custos adicionais (proxies residenciais de US$ 3/GB, créditos CAPTCHA) aumentam a conta em grande escala.
Preços:Plano gratuito disponível; Standard a partir de US$ 69/mês; Professional a partir de US$ 249/mês.
3. Apify: Raspadores personalizados do Actor Marketplace Plus
Apify é uma plataforma focada no desenvolvedor construída em torno de “Atores”, que são scripts de scraping pré-construídos ou personalizados que você implanta e executa na nuvem do Apify. A Actor Store tem milhares de scrapers prontos para sites como Amazon, Google Maps, LinkedIn e Instagram, o que a torna uma ótima opção quando sua lista de vários sites se sobrepõe ao catálogo deles.
Para sites sem ator existente, você escreve o seu próprio em JavaScript ou Python e hospeda-o na infraestrutura do Apify. Esse modelo duplo (marketplace mais customizado) é o que faz o Apify escalar em diversos projetos multi-site.
Tipo:Plataforma de desenvolvedor com mercado Actor.
Ideal para:Equipes de desenvolvedores que desejam scrapers pré-construídos, quando disponíveis, e atores personalizados, quando não.
Principais recursos:
- Milhares de atores pré-construídos para sites importantes;
- Gerenciamento, agendamento e monitoramento de proxy integrados;
- SDK de ator personalizado em Python e JavaScript;
- Integra-se com Make, Zapier e webhooks.
Vantagens:Um enorme catálogo reduz o tempo de desenvolvimento. Ferramentas de desenvolvimento fortes. Pagamento conforme o uso previsível.
Desvantagens:Sobrecarga de manutenção quando os sites de destino mudam. Os custos aumentam com cargas de trabalho pesadas.
Preços:Plano gratuito; Starter US$ 29/mês; Scale US$ 199/mês.
4. Bright Data: infraestrutura empresarial de dados multisite
Bright Data é o peso pesado da infraestrutura de dados da web. Além do Web Scraper IDE, um ambiente visual para a construção de scrapers baseados em JS, a Bright Data fornece um Datasets Marketplace com dados pré-coletados de grandes sites públicos, além de redes proxy residenciais e de ISP e infraestrutura de desbloqueio. É um exagero para trabalhos pequenos, mas incomparável em escala.
Tipo:Infraestrutura de dados corporativos mais IDE visual.
Ideal para:Coleta multisite de missão crítica em grande escala com alvos anti-bot agressivos.
Principais recursos:
- Web Scraper IDE com fluxos de trabalho visuais e de código;
- Datasets Marketplace para dados pré-coletados;
- Redes proxy residenciais, ISP e móveis;
- API de desbloqueio para alvos fortemente protegidos.
Vantagens:A melhor infraestrutura de proxy da categoria. Conjuntos de dados pré-coletados economizam semanas para alvos comuns.
Desvantagens:Preços empresariais. Curva de aprendizado íngreme.
Preços:Nível premium baseado em uso. Cotações personalizadas para alto volume. A API Scraper começa em US$ 0,75/1k rec.
5. ScrapingBee: uma chamada de API, qualquer site
ScrapingBee é uma API de scraping que lida com renderização de JavaScript, rotação de proxy e orquestração de navegador headless por trás de um único endpoint HTTP. Envie um URL, receba HTML limpo ou JSON estruturado para endpoints suportados como Amazon, SERP e imóveis. Para trabalho em vários sites, a interface uniforme é o ponto de venda: a mesma chamada de API em centenas de sites.
Tipo:API de raspagem com renderização JS.
Ideal para:Desenvolvedores que desejam uma única API em vez de manter frotas de navegadores.
Principais recursos:
- Renderização JS automática;
- Rotação de proxies residenciais e de datacenter;
- Endpoints pré-construídos para Amazon e SERPs;
- SDKs simples de HTTP / Python / Node.
Vantagens:Integração de API mais fácil. Preços previsíveis por solicitação.
Desvantagens:Páginas com muito JS consomem créditos rapidamente. Menos flexível do que estruturas completas para casos extremos.
Preços:A partir de US$ 49/mês por aproximadamente 250 mil créditos.
6. Browse.ai: treine robôs para assistir páginas
Browse.ai permite registrar um caminho através de um site (clicar, selecionar, paginar) e salvá-lo como um “robô” que você pode executar novamente de acordo com uma programação. Para casos de uso de monitoramento de vários locais (rastrear preços de concorrentes em 20 locais, observar quadros de empregos para novas postagens), é difícil superar a velocidade de configuração.
Tipo: Raspador com interface de treinar um robô.
Ideal para:Monitoramento recorrente de alvos específicos de vários locais.
Principais recursos:
- Treinamento de robô apontar e clicar;
- Robôs pré-construídos para sites comuns;
- Execuções agendadas com alertas por e-mail/Slack;
- Integrações com Planilhas Google, Airtable, Zapier.
Vantagens:Genuinamente amigável para iniciantes. Forte para monitorar fluxos de trabalho.
Desvantagens:Menos flexível para lógicas de extração complexas. Cada robô é por site, portanto, projetos multisite precisam de um robô por destino.
Preços:100 créditos diários gratuitos; planos pagos a partir de US$ 16/mês.
7. ParseHub: raspador visual de nível gratuito
ParseHub é um raspador visual de desktop que lida com AJAX, rolagem infinita e fluxos de login por meio de uma interface de apontar e clicar. Possui um nível gratuito notavelmente generoso (200 páginas por tiragem, 5 projetos públicos), o que o torna ideal para projetos de pesquisa únicos em vários locais com orçamento limitado.
Tipo:Raspador visual para desktop.
Ideal para:Projetos multisite de nível gratuito com complexidade moderada.
Principais recursos:
- Construtor visual de fluxo de trabalho de apontar e clicar;
- Lida com JS, AJAX, rolagem infinita;
- Acesso API em planos pagos;
- Execuções na nuvem no plano Standard e superiores.
Vantagens:Plano gratuito forte. Lida com conteúdo dinâmico melhor do que a maioria dos raspadores visuais.
Desvantagens:Mais lento que os concorrentes nativos da nuvem. Somente desktop no nível gratuito.
Preços:Grátis; Standard US$ 189/mês; Professional US$ 599/mês.
8. Zyte: Scrapy, além de infraestrutura gerenciada
Zyte é a empresa por trás do Scrapy, a estrutura de scraping Python de código aberto mais usada. Seu produto comercial envolve o Scrapy com tempo de execução gerenciado, extração alimentada por IA e uma rede proxy global. Se sua equipe já mora em Scrapy, Zyte é o caminho de “executar spiders em um laptop” para “executá-los em escala”.
Tipo:Scrapy mais infra gerenciado mais extração de IA.
Ideal para:Equipes de engenharia dimensionando projetos Scrapy existentes em vários locais.
Principais recursos:
- Scrapy Cloud para hospedagem spider;
- Gerenciador de proxy inteligente com IPs rotativos;
- API de extração automática (com tecnologia de IA);
- Latência inferior a 100 ms na borda global.
Vantagens:Sem multas por excesso; uso excedente cobrado com taxas de desconto. Ecossistema de desenvolvimento forte.
Desvantagens:Curva de aprendizado mais acentuada para usuários que não usam Scrapy.
Preços:Pagamento conforme o uso de US$ 0,13 a US$ 1,27 por 1 mil respostas HTTP; o volume compromete-se a partir de US$ 0,06/1K.
9. Scrapy: o carro-chefe do código aberto
Scrapy é uma estrutura Python gratuita e de código aberto para a construção de rastreadores da web escaláveis. É assíncrono, tem uso eficiente de memória e foi testado em batalha para projetos multilocais de grande escala. Sem preço, sem dependência de fornecedor. Apenas código.
Tipo:Estrutura Python de código aberto.
Ideal para:Equipes de engenharia criando rastreadores personalizados em vários sites.
Principais recursos:
- Assíncrono e de alto rendimento;
- Sistema de middleware extensível;
- Pipelines integrados e exportações de itens;
- Enorme comunidade e ecossistema de biblioteca.
Vantagens:Grátis. Testado em batalha. Flexibilidade incomparável.
Desvantagens:Python necessário. Sem GUI. Você possui as operações.
Preços:Grátis.
10. Playwright: Automação de navegador para sites difíceis
Playwright é a estrutura de automação de navegador de código aberto da Microsoft. Ele controla Chromium, Firefox e WebKit sem cabeça, lida com sites com muito JavaScript e oferece suporte a Python, Node.js, Java e .NET. Para projetos de vários sites onde alguns alvos são fortemente renderizados em JS ou controlados por login, o Playwright geralmente é a resposta.
Tipo:Automação de navegador de código aberto.
Ideal para:Engenheiros raspando sites com uso pesado de JS ou com bloqueio de login.
Principais recursos:
- Suporte para vários navegadores e vários idiomas;
- Interceptação de rede e simulação de solicitação;
- Espera automaticamente por elementos (menos instável que Selenium);
- Codegen para rascunhos rápidos de scraper.
Vantagens:Grátis. Confiável em sites difíceis. API moderna.
Desvantagens:Muitos recursos. Você mesmo escreve a orquestração.
Preços:Grátis.
Como você lida com CAPTCHAs em diferentes sites?
Você lida com CAPTCHAs em diferentes sites encaminhando cada desafio de CAPTCHA por meio de um único serviço de solução, independentemente de qual fornecedor de CAPTCHA o site usa. Dessa forma, seu raspador não se importa se atingiu o reCAPTCHA em um site e o Cloudflare Turnstile no próximo. Ambos voltam como um token para injetar.
Em um pipeline de vários sites, você normalmente verá o seguinte:
- Google reCAPTCHA v2 / v3 / Enterprise:mais comum;
- Cloudflare Turnstile:participação em rápido crescimento;
- DataDome / Imperva (Incapsula):comércio eletrônico e viagens de alto padrão;
- GeeTest / Tencent CAPTCHA:comum em sites asiáticos;
- hCaptcha / Prosopo / Altcha:alternativas focadas na privacidade.
Tentar inserir um solucionador único em cada raspador é o que mata pipelines de vários locais. Um serviço unificado como CapMonster Cloud expõe uma API que lida com todos os principais tipos de CAPTCHA. Seu raspador envia o URL da página e a chave do site, recebe de volta um token resolvido e continua.
Algumas dicas práticas para manipulação de CAPTCHA multisite:
- Detecte cedo e resolva uma vez.Construa a detecção CAPTCHA no manipulador de resposta do raspador para que você não analise páginas com falha.
- Armazene tokens resolvidos em cache onde o site permitir.Alguns tokens CAPTCHA permanecem válidos por alguns minutos. Reutilize-os dentro dessa janela.
- Observe as taxas de falha por alvo.Um site cuja taxa de sucesso de CAPTCHA cai repentinamente geralmente está testando novos sinais de bot. Gire sua pilha de impressões digitais antes de enviar mais tráfego.
Qual é a aparência de um fluxo de trabalho prático para executar um web scraper em mais de 50 sites?
Um fluxo de trabalho prático para executar um web scraper em mais de 50 sites combina o scraper certo para cada tipo de site com uma camada de proxy unificada, uma camada unificada de resolução de CAPTCHA e uma etapa de desduplicação e exportação que normaliza a saída. Cada site se torna um plug-in, não uma reescrita.
Aqui está a arquitetura de alto nível que recomendamos.
Passo a passo:
Segmente sua lista de alvos.Agrupe sites por complexidade. Sites estáticos e compatíveis com modelos podem ir para um raspador no-code como o Octoparse. Layouts altamente dinâmicos ou incomuns podem ir para um agente de web scraping com IA, onde você apenas descreve o que deseja em linguagem natural. Sites com login controlado e com uso pesado de JS pertencem ao Playwright ou a uma API gerenciada como Bright Data.
Padronize o esquema de saída.Decida antecipadamente quais colunas cada registro precisa (source_url, title, price_usd, scraped_at). Force cada raspador a emitir este esquema. Colunas incompatíveis são onde os pipelines de vários locais se desintegram.
Centralize a rotação de proxy.Use um único provedor de proxy residencial em todos os scrapers. Os proxies por raspador criam pontos cegos e qualidade de sessão irregular.
Centralize a resolução de CAPTCHA.Encaminhe cada encontro CAPTCHA por meio de uma API. CapMonster Cloud ou equivalente oferece um único endpoint de token para cada tipo de CAPTCHA que seus scrapers veem.
Limite de taxa por site, não globalmente.Um limite de taxa global retarda seus sites rápidos para corresponder aos lentos. Os limites por site respeitam a tolerância de cada alvo.
Deduplicação na ingestão.Registros hash em uma chave estável (source_url + product_id) antes de chegarem ao seu armazém.
Monitore a taxa de sucesso por site.Acompanhe o sucesso da raspagem como um KPI por site. Uma queda repentina geralmente significa que o site enviou novas defesas contra bots, e não que seu scraper “quebrou”.
O que percebi quando adotamos essa arquitetura no projeto de 38 locais que mencionei no início: a maior parte da carga de manutenção passou de “consertar raspadores” para “observar o gráfico de taxa de sucesso por local”. Quando o número de um site caía, sabíamos exatamente em qual raspador tocar. O resto continuou correndo.
O que evitar:
• Um mega-raspador tentando lidar com todos os sites. Problemas diferentes, ferramentas diferentes.
• Seletores codificados quando uma extração semântica de IA generalizaria melhor.
• Ignorando a revisão jurídica. Colete apenas dados públicos, respeite o robots.txt e os termos de serviço e nunca colete dados pessoais sem base legal.
Conclusão: Escolhendo as ferramentas certas de Web Scraping para dados de vários sites
As melhores ferramentas de web scraping para extração de dados de vários sites em 2026 não são uma categoria única. Eles são uma pilha. Os não programadores que executam lotes de dezenas de milhares de registros obtêm o máximo aproveitamento de um raspador de IA como o Chat4Data. As equipes que executam scraps recorrentes em layouts semelhantes ganham com os modelos do Octoparse. As equipes de engenharia que enviam milhões de registros viverão em Scrapy, Zyte ou Bright Data.
O padrão que quebra os pipelines é usar uma ferramenta para tudo. O padrão escalável é combinar ferramentas com tipos de site, centralizar proxies e resolução de CAPTCHA e tratar cada site como um módulo de plug-in por trás de um esquema normalizado.
Escolha o raspador de web que se adapta à menor unidade do seu problema. Padronize tudo ao seu redor. Adicione uma conta CapMonster Cloud à pilha antes que seus raspadores atinjam a primeira parede, não depois.
NB: Web scraping deve ser usado apenas para automatizar testes em seus próprios sites e em sites aos quais você tenha acesso legal. Sempre respeite o robots.txt, os termos de serviço e as leis de proteção de dados aplicáveis.






