How to save extracted information?
To save extracted information, you need to understand a few data storage formats:
CSV – one of the most popular formats for storing tabular data. It is a text file where each row corresponds to a record and values are separated by commas. Advantages of this format: supported by most data processing programs, including Excel; easy to read and edit with text editors. Disadvantages: limited capabilities for storing complex structures (e.g., nested data); issues with escaping commas and special characters.
JSON – a text-based data exchange format used to represent structured data. It is widely used in web development. Pros: supports nested and hierarchical data structures; well supported by most programming languages; easy for both humans and machines to read. JSON is suitable for storing data that may need to be transferred via APIs. Cons: JSON files can be larger compared to CSV; slower to process compared to CSV due to its more complex structure.
XLS – used for Excel spreadsheets where cell data, formatting, and formulas are stored. It is often used for storing databases. To work with XLS in Python, external libraries are required, such as pandas. This format allows data to be stored in a readable and presentable form. The main disadvantage is the need for additional libraries, which increases server load and processing time.
XML – a markup language used for storing and transferring data. It supports nested structures and attributes. Pros: structured format, allows complex data storage, widely supported by various standards and systems. Cons: XML files can be bulky and difficult to process; processing XML can be slow due to its structure.
Databases are used to store large volumes of structured data. Examples include MySQL, PostgreSQL, MongoDB, SQLite. Pros: support for large data volumes and fast access; easy to organize and link data; support for transactions and data recovery. Cons: requires additional setup and maintenance effort.
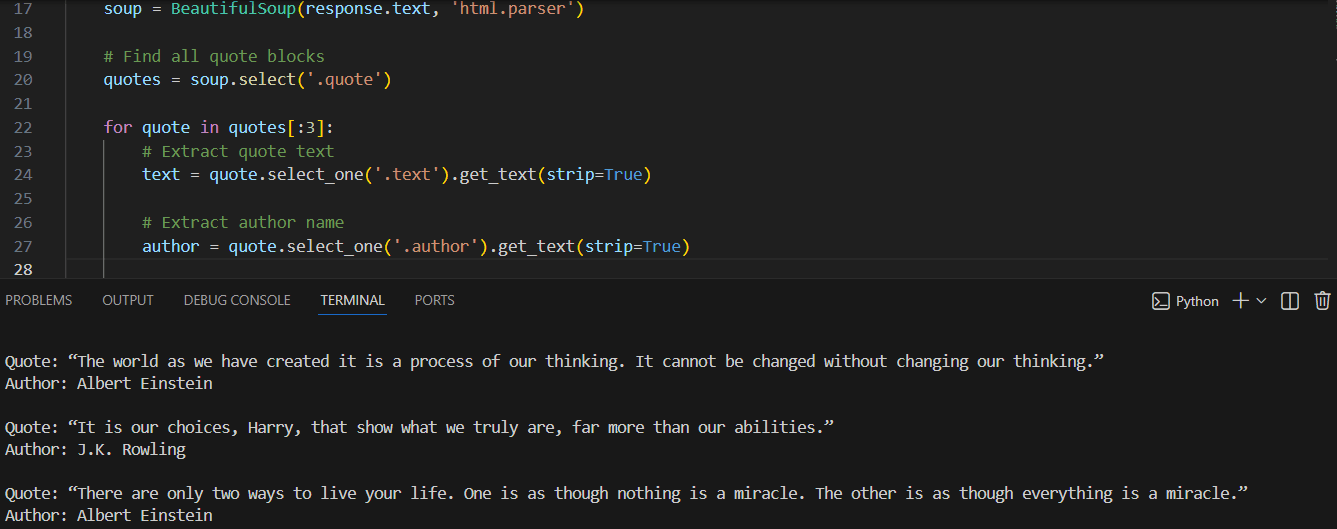
For our scrapers, we will choose the CSV format because the extracted data is tabular in nature (quote text and author, product names and links) and the data volume is relatively small, without nested structures. Additional information about reading and writing this format can be found here. Let’s add CSV import to our code with quotes, create a writer object, and write the quote data (quotes themselves and their authors):
with open('quotes.csv', 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['Quote', 'Author'])
for quote in quotes[:3]:
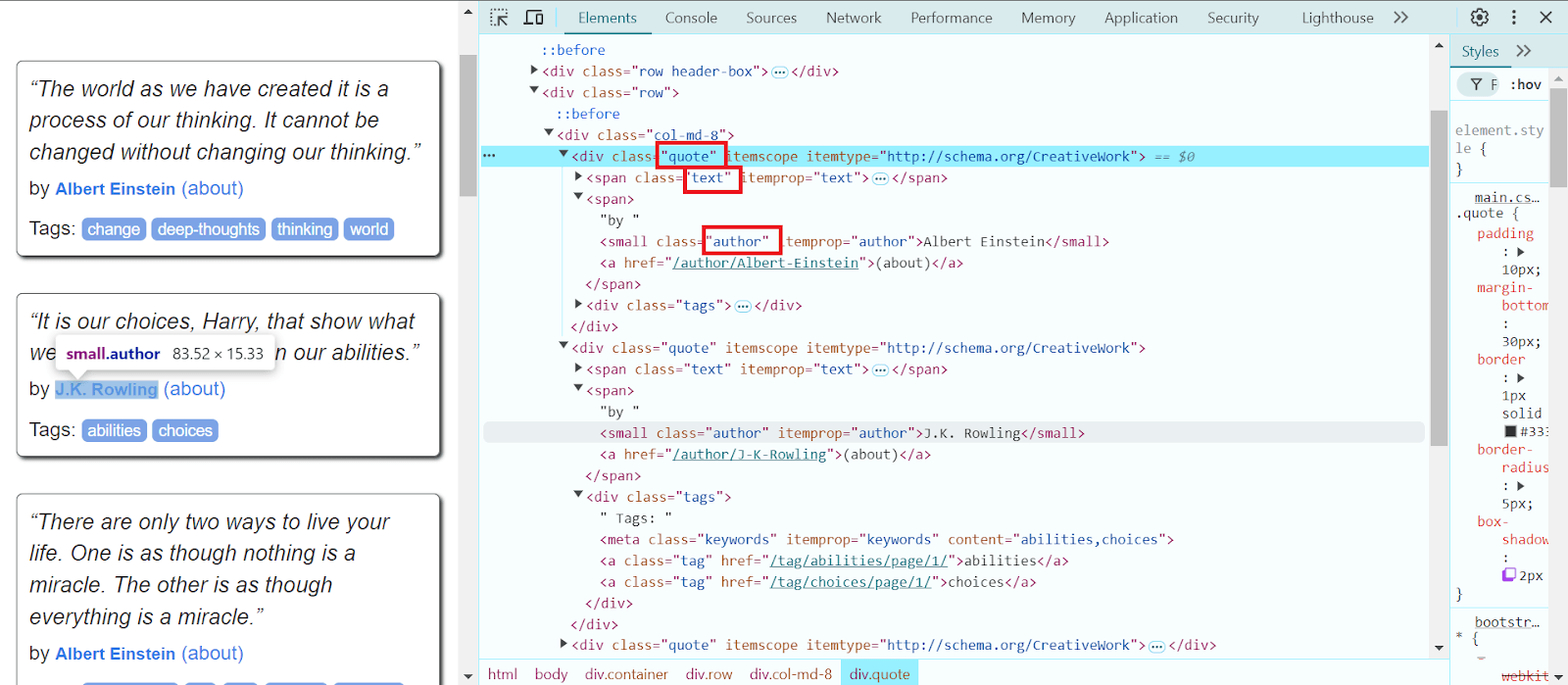
text = quote.select_one('.text').get_text(strip=True)
author = quote.select_one('.author').get_text(strip=True)
csvwriter.writerow([text, author])
We also add additional console outputs and error handling:
print("Data successfully written to quotes.csv")
except requests.RequestException as e:
print(f'Request error: {e}')
except Exception as e:
print(f'An error occurred: {e}')
Full code:
import requests
from bs4 import BeautifulSoup
import csv
# Target page URL
url = 'https://quotes.toscrape.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
}
try:
# Send GET request with user-agent
response = requests.get(url, headers=headers)
response.raise_for_status() # Check for HTTP errors
# Create BeautifulSoup object for parsing HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Find all quote blocks
quotes = soup.select('.quote')
# Open CSV file for writing
with open('quotes.csv', 'w', newline='', encoding='utf-8') as csvfile:
# Create writer object
csvwriter = csv.writer(csvfile)
# Write headers
csvwriter.writerow(['Quote', 'Author'])
# Write quote data
for quote in quotes[:3]:
# Extract quote text
text = quote.select_one('.text').get_text(strip=True)
# Extract author name
author = quote.select_one('.author').get_text(strip=True)
# Write to CSV file
csvwriter.writerow([text, author])
print("Data successfully written to quotes.csv")
except requests.RequestException as e:
print(f'Request error: {e}')
except Exception as e:
print(f'An error occurred: {e}')
The same steps will be applied to the second scraper:
from playwright.sync_api import sync_playwright
import csv
# Target page URL
url = 'https://parsemachine.com/sandbox/catalog/'
def scrape_with_playwright():
try:
with sync_playwright() as p:
# Launch Chromium browser
browser = p.chromium.launch(headless=False) # Set to True if you need headless mode
try:
# Open a new tab
page = browser.new_page()
# Navigate to target page
page.goto(url)
# Find all product cards
product_cards = page.query_selector_all('.card.product-card')
# Open CSV file for writing
with open('products.csv', 'w', newline='', encoding='utf-8') as csvfile:
# Create writer object
csvwriter = csv.writer(csvfile)
# Write headers
csvwriter.writerow(['Title', 'Link'])
# Extract data from product cards and write to CSV
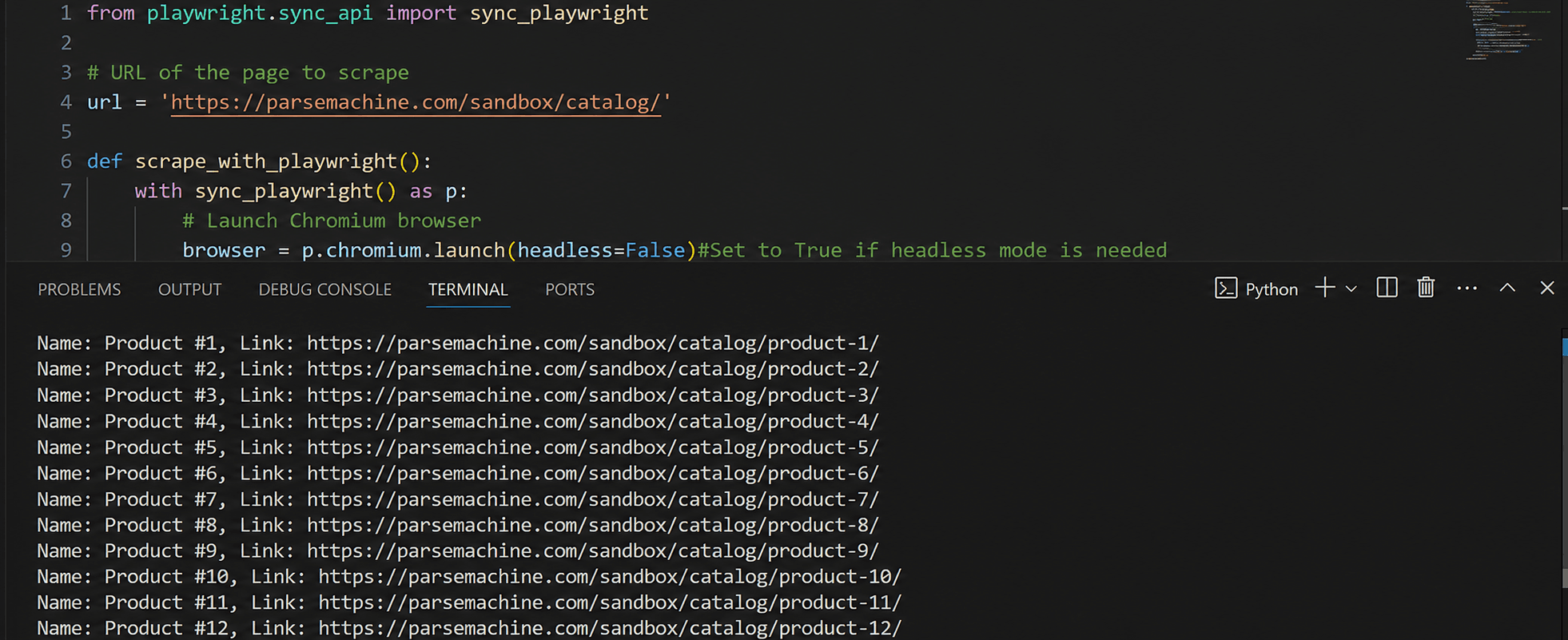
for card in product_cards:
# Extract product title
title_tag = card.query_selector('.card-title .title')
title = title_tag.inner_text() if title_tag else 'No title'
# Product link
product_link = title_tag.get_attribute('href') if title_tag else 'No link'
# If the link is relative, add base URL
if product_link and not product_link.startswith('http'):
product_link = f'https://parsemachine.com{product_link}'
# Write data to CSV file
csvwriter.writerow([title, product_link])
# Print product information
print(f'Title: {title}, Link: {product_link}')
print("Data successfully written to products.csv")
except Exception as e:
print(f'Error while working with Playwright: {e}')
finally:
# Close browser
browser.close()
print("Browser closed.")
except Exception as e:
print(f'Error starting Playwright: {e}')
scrape_with_playwright()