Como salvar as informações extraídas?
Para salvar as informações extraídas, é necessário conhecer um pouco sobre os formatos de armazenamento de resultados:
CSV – um dos formatos mais populares para armazenar dados tabulares. Ele é um arquivo de texto em que cada linha corresponde a um registro e os valores são separados por vírgulas. Vantagens: suportado pela maioria dos programas de análise de dados, incluindo Excel, fácil de ler e editar em editores de texto. Desvantagens: capacidades limitadas para armazenar estruturas complexas de dados (por exemplo, dados aninhados). Problemas com escape de vírgulas e caracteres especiais.
JSON – é um formato de troca de dados em texto, útil para representar dados estruturados. É amplamente usado no desenvolvimento web. Vantagens: suporta estruturas aninhadas e hierárquicas; amplamente suportado por várias linguagens de programação; fácil de ler tanto por humanos quanto por máquinas. JSON é adequado para dados que podem ser transmitidos via API. Desvantagens: JSON pode gerar arquivos maiores que CSV; é mais lento para processar devido à estrutura mais complexa.
XLS – destinado a tabelas do Excel, onde são armazenados dados de células, formatação e fórmulas. É frequentemente usado para armazenar bancos de dados. Para trabalhar com XLS em Python, são necessárias bibliotecas externas, como pandas. Esse formato permite armazenar dados de forma legível e apresentável. A principal desvantagem é a necessidade de bibliotecas adicionais, o que aumenta a carga no servidor e o tempo de processamento dos dados.
XML – é uma linguagem de marcação usada para armazenar e transmitir dados. Suporta estruturas aninhadas e atributos. Vantagens: estruturado, permite armazenar dados complexos, bem suportado por diversos padrões e sistemas. Desvantagens: XML pode ser pesado e complexo de processar; a análise pode ser lenta devido à sua estrutura.
Bancos de dados são usados para armazenar grandes volumes de dados estruturados. Exemplos incluem MySQL, PostgreSQL, MongoDB, SQLite. Vantagens: suporte a grandes volumes de dados e acesso rápido; facilidade para organizar e relacionar dados; suporte a transações e recuperação de dados. Desvantagem: exige esforço adicional de configuração e manutenção.
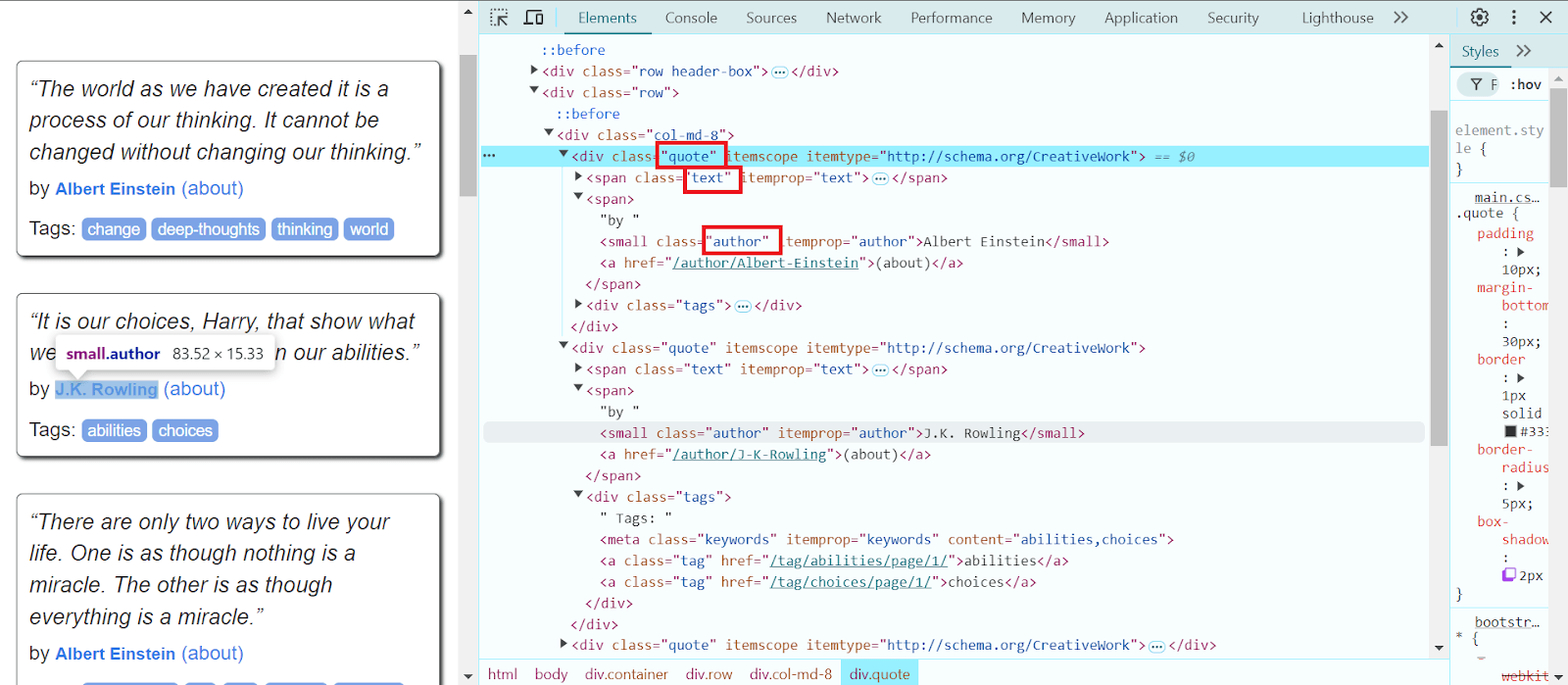
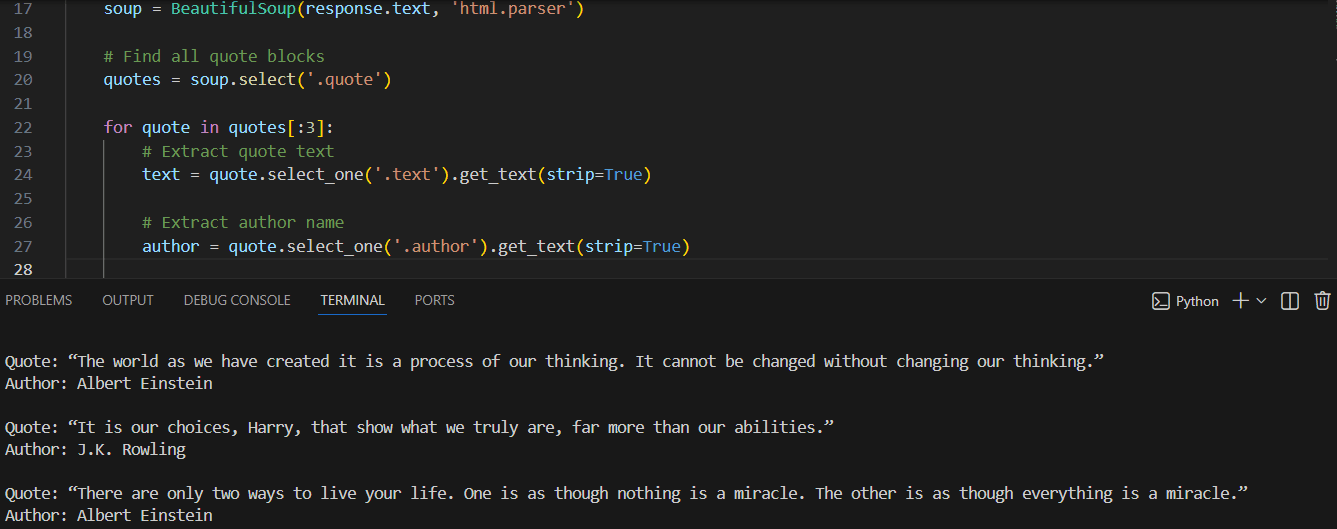
Para nossos scrapers, escolheremos o formato CSV, porque os dados extraídos são tabulares (texto da citação e autor, nomes de produtos e seus links) e o volume de dados é relativamente pequeno, sem estruturas aninhadas. Mais informações sobre como ler e escrever nesse formato podem ser encontradas aqui. Vamos adicionar ao nosso código de citações a importação do CSV, criar um objeto writer e gravar os dados das citações (texto e autores):
with open('quotes.csv', 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['Citação', 'Autor'])
for quote in quotes[:3]:
text = quote.select_one('.text').get_text(strip=True)
author = quote.select_one('.author').get_text(strip=True)
csvwriter.writerow([text, author])
Também adicionaremos saídas no console e tratamento de possíveis erros:
print("Dados gravados com sucesso em quotes.csv")
except requests.RequestException as e:
print(f'Erro ao requisitar a página: {e}')
except Exception as e:
print(f'Ocorreu um erro: {e}')
Código completo:
import requests
from bs4 import BeautifulSoup
import csv
url = 'https://quotes.toscrape.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/147.0.0.0 Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
quotes = soup.select('.quote')
with open('quotes.csv', 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['Citação', 'Autor'])
for quote in quotes[:3]:
text = quote.select_one('.text').get_text(strip=True)
author = quote.select_one('.author').get_text(strip=True)
csvwriter.writerow([text, author])
print("Dados gravados com sucesso em quotes.csv")
except requests.RequestException as e:
print(f'Erro ao requisitar a página: {e}')
except Exception as e:
print(f'Ocorreu um erro: {e}')
Faremos o mesmo com o segundo scraper:
from playwright.sync_api import sync_playwright
import csv
url = 'https://parsemachine.com/sandbox/catalog/'
def scrape_with_playwright():
try:
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
try:
page = browser.new_page()
page.goto(url)
product_cards = page.query_selector_all('.card.product-card')
with open('products.csv', 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['Nome', 'Link'])
for card in product_cards:
title_tag = card.query_selector('.card-title .title')
title = title_tag.inner_text() if title_tag else 'Sem nome'
product_link = title_tag.get_attribute('href') if title_tag else 'Sem link'
if product_link and not product_link.startswith('http'):
product_link = f'https://parsemachine.com{product_link}'
csvwriter.writerow([title, product_link])
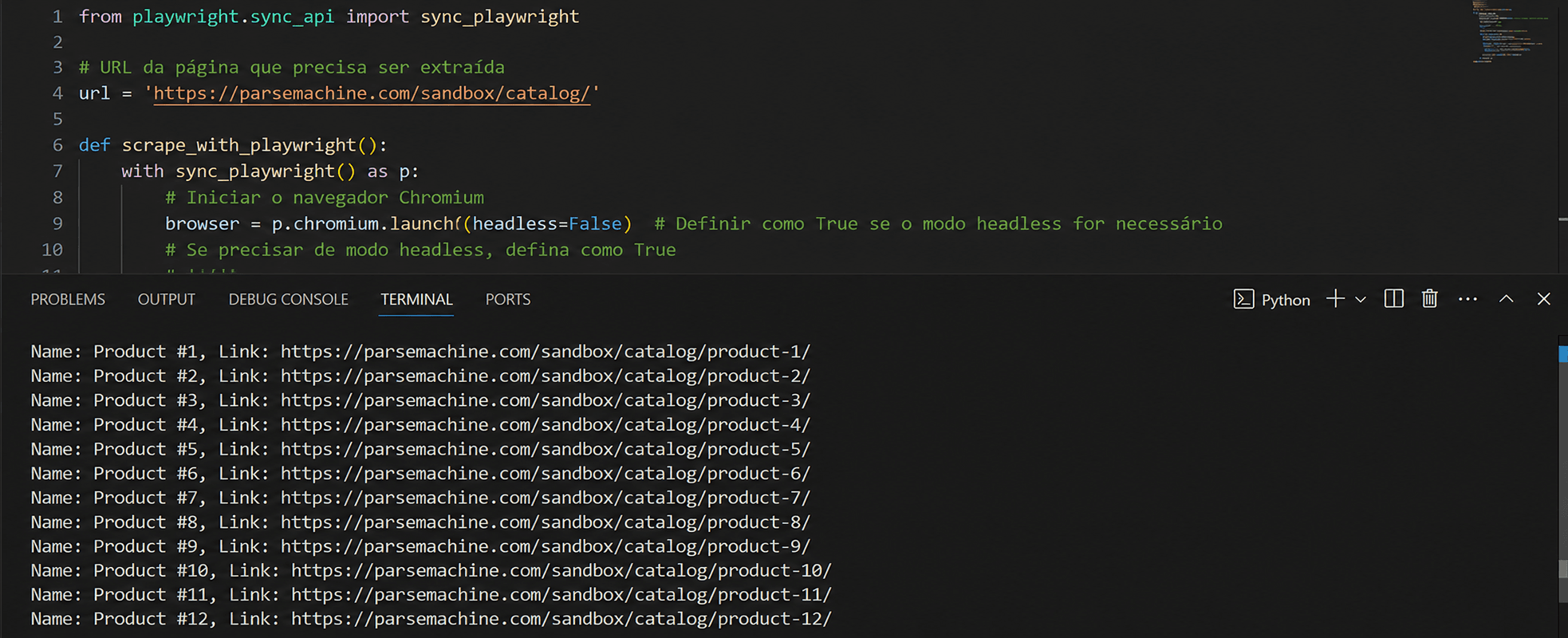
print(f'Nome: {title}, Link: {product_link}')
print("Dados gravados com sucesso em products.csv")
except Exception as e:
print(f'Erro ao trabalhar com Playwright: {e}')
finally:
browser.close()
print("Navegador fechado.")
except Exception as e:
print(f'Erro ao iniciar Playwright: {e}')
scrape_with_playwright()