 CapMonster Cloud API
CapMonster Cloud API 适用于浏览器的扩展程序
适用于浏览器的扩展程序 reCAPTCHA
reCAPTCHA Cloudflare
Cloudflare Text Captcha
Text Captcha Amazon
Amazon
使用 Python 进行网页爬取:完整指南
网页爬取是一种从互联网上收集数据的实用方法,常用于网站索引、变更追踪或大规模信息收集。 在本文中,我们将介绍网页爬取的基础知识,为您推荐一些实用的 Python 工具和库,并提供简单的示例,帮助您快速入门!
网页爬取是指自动搜索互联网并从网站收集信息的过程。它涉及在同一网站(甚至不同网站)的多个页面上进行探索,以收集大量数据。大规模爬取通常由搜索引擎或其他公司用于网站索引和数据收集,以满足各种需求。
例如,Googlebot 每天访问数十亿个网页,通过跟随页面和网站之间的链接来保持 Google 搜索结果的最新性。Googlebot 先从一些关键的 URL 开始访问,然后沿着这些页面上的链接发现新页面。它使用智能算法来决定应该索引哪些页面以及索引的频率,以便为用户提供最相关的搜索结果。
Python 是进行网页爬取的理想选择,因为它易于学习,并且拥有丰富的相关库。例如,Scrapy、BeautifulSoup 和 Selenium 等工具可以简化网页爬取和数据采集的过程,无论任务是简单还是复杂。
网页爬取(Web Crawling)和网页抓取(Web Scraping)密切相关,但它们并不完全相同。
网页爬取类似于蜘蛛在网站(或多个网站)之间爬行,从一个页面跳转到另一个页面,以收集数据。它主要用于探索和索引大量信息,通常是通过跟随页面之间的链接来实现的。
网页抓取则更关注从网页上提取特定的数据。它类似于放大细节,例如收集商品价格、联系信息或网页上的文本内容。
因此,爬取 是在多个页面上搜索和收集数据的过程,而 抓取 是从这些页面中提取具体信息的过程。
让我们来看一个基本的网页爬虫如何从网站收集信息的示例。
从种子URL开始
假设您想收集网站上的博客文章信息。您的起始URL(种子URL)可以是博客的主页,例如 https://example.com。
发送网页请求
爬虫向 https://example.com 发送一个HTTP请求,请求服务器返回主页的HTML内容。服务器响应并发送该页面的HTML代码。
解析HTML内容
然后,爬虫解析主页的HTML。它会查找特定的元素,例如博客文章的链接(通常包含在 <a> 标签中)以及其他有用的信息,如页面标题或元数据。
提取链接
从主页上,爬虫找到了指向其他页面的链接——例如,它找到了以下链接:
https://example.com/blog/post1
https://example.com/blog/post2
https://example.com/about
爬虫将这些链接添加到它的访问页面列表中。
跟随链接
现在,爬虫请求第一个博客文章,https://example.com/blog/post1。它再次发送一个HTTP请求并获取该页面的HTML内容。
解析博客文章
在博客文章页面,爬虫查找额外的链接(例如,指向其他博客文章、类别或标签的链接)和数据(例如,文章标题、作者和发布日期)。这些数据被提取并保存。
提取更多链接
从 https://example.com/blog/post1 页面,爬虫找到了指向其他文章的链接:
https://example.com/blog/post3
https://example.com/blog/post4
这些新链接被添加到待爬取的URL列表中。
存储数据
爬虫收集文章的标题、作者、日期和内容,并将它们存储在结构化格式中,例如数据库或CSV文件。
避免重复抓取
爬虫跟踪它已经访问过的URL。如果它再次遇到 https://example.com/blog/post1,它会跳过该链接,以避免重复爬取同一页面。
在开始爬取之前,爬虫会检查 https://example.com/robots.txt 文件,以确保它被允许抓取该网站。如果该文件禁止抓取网站的某些部分(例如,管理员面板),爬虫会避免访问这些区域。
爬虫继续此过程,访问页面、提取链接并收集数据,直到收集完网站上的所有信息或达到设定的限制。
这个基本过程使爬虫能够自动化地从网站收集大量数据,通过跟随链接并提取所需内容。
Python 提供了多种强大的库,无论是标准库还是第三方库,都可以简化从网站收集数据的过程。以下是标准库和一些流行的第三方库的概述,可以用于网络爬虫:
标准库
urllib
urllib 是 Python 的内置库,提供用于处理 URL 的功能。它可以用于发送 HTTP 请求、解析 URL 和处理响应。虽然它不是专门为网络爬虫设计的,但它允许加载页面,因此可以作为简单爬虫的基础工具。
http.client
http.client 是另一个标准库,可用于处理 HTTP 请求。它提供了更多的控制权,允许在请求/响应循环中进行更灵活的数据获取。
第三方库
Requests
requests 库是 Python 中最流行的第三方库之一,用于发送 HTTP 请求。它简化了与网页交互的过程,常用于网页抓取和爬虫任务。requests 使得处理 GET、POST 和其他 HTTP 请求变得非常容易。
BeautifulSoup
虽然 BeautifulSoup 本身不是爬虫,它通常与爬虫一起使用,用于解析和提取 HTML 页面上的数据。它简化了文档树的导航和搜索,提取链接和解析内容。
Scrapy
Scrapy 是一个强大且灵活的网络爬虫框架,专为大规模的网页抓取和爬虫任务设计。它允许定义蜘蛛(爬虫),这些蜘蛛可以自动遍历网站并提取数据。Scrapy 涵盖了从发送请求到存储提取数据的所有内容,非常适合复杂的爬虫项目。
Selenium
Selenium 主要被用作自动化浏览器的工具,用于网页测试,但它也常用于处理动态网页的爬虫任务(即使用 JavaScript 的网站)。它能够与 JavaScript 互动,并加载那些在原始 HTML 中未显示的内容。
Python 中的 re 库对于在网络爬虫中提取、处理和操作文本非常有用。以下是它的应用方式:
- 提取链接:使用正则表达式查找 HTML 页面中所有的 href 属性(链接)。
- 提取数据:使用模板轻松提取特定数据,如价格或商品名称。
- 清理数据:删除提取内容中的不必要的空格或标签。
- 处理动态内容:提取嵌入在 JavaScript 或复杂 HTML 结构中的数据。
- 过滤元素:使用模板查找具有特定属性(如类名或 ID)的元素。
尽管正则表达式功能强大且快速,但使用时应谨慎,因为它们可能难以调试,且并不适用于所有 HTML 解析任务。
在本教程中,我们将介绍如何创建一个简单的 Python 网络爬虫。这个爬虫将访问一个网站,提取链接并点击它们以收集更多的数据。我们将使用 requests 库来加载页面,并使用 BeautifulSoup 来解析 HTML。在本示例中,爬虫将从 https://www.wikipedia.org/ 开始,并收集每个页面上找到的所有链接,然后继续在网站上爬取。
在开始之前,请确保您已经准备好:
- Python 3+:从官方网站下载安装程序,运行并按照安装指南进行安装。
- Python IDE:您可以使用 Visual Studio Code 配合 Python 扩展或 PyCharm Community Edition。
- requests 和 BeautifulSoup 的文档:查阅官方文档,了解如何使用它们。
1. 安装所需的库
在开始之前,您需要安装 requests 和 BeautifulSoup 库。您可以使用 pip 安装它们:
pip install requests beautifulsoup42. 设置日志记录
日志记录将帮助我们跟踪爬虫的活动。我们将设置基础日志记录,以便在爬虫运行时显示有用的消息。这样可以设置日志格式和日志级别为 INFO,这将显示重要的消息。
import logging
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)3. 创建爬虫类
爬虫将包含在一个类中,我们将称其为 SimpleCrawler。在这个类中,我们将定义方法来加载页面、提取链接和管理爬虫过程。
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set() # 用于跟踪已经访问过的 URL
self.to_visit = start_urls # 存储需要访问的 URL 列表4. 加载网页
接下来的步骤是创建一个方法,通过 requests 库加载页面内容。
def fetch_page(self, url):
"""加载页面内容。"""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"无法加载 {url}: {e}")
return Nonefetch_page 方法向指定的 URL 发送 GET 请求。如果请求成功,它将返回页面的 HTML 内容。否则,会记录错误并返回 None。
5. 提取页面上的链接
接下来,我们需要从 HTML 页面中提取链接(URL)。为此,我们将使用 BeautifulSoup 来解析 HTML 并查找所有带有 href 属性的 <a> 标签。
from urllib.parse import urljoin
def extract_links(self, url, html):
"""提取并返回页面上的所有链接。"""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
yield full_urlBeautifulSoup(html, 'html.parser') 用来解析 HTML 内容。
soup.find_all('a', href=True) 用来查找所有带有 href 属性的 <a> 标签。
urljoin(url, link) 确保相对 URL 正确地转换为绝对 URL。
6. 将 URL 添加到队列
我们需要将新的 URL 添加到待访问的列表中,但前提是它们还没有被访问过。
def add_to_queue(self, url):
"""如果 URL 尚未被访问或添加到队列中,则将其添加到待访问列表。"""
if url not in self.visited and url not in self.to_visit:
self.to_visit.append(url)该方法确保我们不会重复访问已经处理过或已添加到队列中的 URL。
7. 处理每个页面
现在,我们编写一个方法来处理每个页面。它将加载页面,提取链接并将它们添加到队列中。
def process_page(self, url):
"""处理页面并收集链接。"""
logging.info(f'处理页面: {url}')
html = self.fetch_page(url)
if html:
for link in self.extract_links(url, html):
self.add_to_queue(link)这个方法调用 fetch_page 来加载页面内容,然后提取并将找到的链接添加到队列中。
8. 爬虫循环
主循环将继续,直到所有 URL 都被访问。它会从 to_visit 列表中提取 URL,处理它并标记为已访问。
def crawl(self):
"""从初始 URL 开始进行网页爬取。"""
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
self.process_page(url)
self.visited.add(url)循环将继续,直到还有 URL 需要访问。每个 URL 都会被处理,链接会被提取并添加到队列中。处理完的 URL 会被标记为已访问。
9. 启动爬虫
最后,我们创建 SimpleCrawler 类的实例并从给定的 URL 列表开始爬取。
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
crawler.crawl()这段代码初始化了爬虫并开始从给定的 URL 列表进行爬取。
完整代码示例:
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
def fetch_page(self, url):
"""加载页面内容。"""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"无法加载 {url}: {e}")
return None
def extract_links(self, url, html):
"""提取并返回页面上的所有链接。"""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
yield full_url
def add_to_queue(self, url):
"""如果 URL 尚未被访问或添加到队列中,则将其添加到待访问列表。"""
if url not in self.visited and url not in self.to_visit:
self.to_visit.append(url)
def process_page(self, url):
"""处理页面并收集链接。"""
logging.info(f'处理页面: {url}')
html = self.fetch_page(url)
if html:
for link in self.extract_links(url, html):
self.add_to_queue(link)
def crawl(self):
"""从初始 URL 开始进行网页爬取。"""
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
self.process_page(url)
self.visited.add(url)
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
crawler.crawl()输出示例:
这个爬虫执行基本的网页链接提取任务,但它也有一些限制,这些限制可能会影响其性能、稳定性和可扩展性。
- 没有深度或页面限制
爬虫会无限制地继续抓取页面,这可能会导致服务器过载或出现无限循环。 - 低效的链接处理
所有找到的链接都会添加到待访问队列中,但爬虫不会检查这些链接是否已经被处理过。 - 单线程(串行)抓取
爬虫仅在一个线程中工作,这在大规模抓取时会导致速度较慢。 - 没有错误处理或超时管理
爬虫仅记录错误并继续执行,改进方法可以是增加重试逻辑。 - 没有处理robots.txt
爬虫不检查网站是否允许抓取。 - 没有请求之间的延迟
爬虫在请求之间没有延迟,这可能会导致服务器过载并被封锁。 - 不支持动态内容
爬虫只处理静态内容,无法处理通过 JavaScript 生成的动态页面。
- 使用多任务处理或多线程:
通过使用并行处理(例如使用 concurrent.futures 或 asyncio 进行异步扫描),可以显著加快抓取过程。多线程程序可以同时处理多个页面,从而提高性能。 示例:使用 aiohttp 和 asyncio 进行异步请求。 - 使用更高级的库:
- Scrapy:最受欢迎的网页抓取和数据收集库,内置支持并行处理、会话管理、错误处理等功能。
- Playwright 或 Selenium:适用于处理使用 JavaScript 生成内容的动态页面。
- 添加深度递归检查或限制访问页面数:
通过限制抓取深度或访问的页面数量,可以避免抓取过程中的无限循环。 - 引入请求间的延迟:
在请求之间添加随机延迟或固定超时,有助于避免服务器过载并减少 IP 被封锁的风险。 - 改进错误处理和重试逻辑:
实现网络错误或服务器端错误(如 500 或 503)时的重试机制。requests 库通过 urllib3 支持重试。 - 使用数据库或文件系统管理队列:
为了提高可扩展性,可以使用数据库(如 SQLite 或 Redis)来管理待访问的链接,而不是将链接存储在内存中。 - 并行处理:
使用如 Celery 或 Dask 等库进行分布式处理,以应对大规模的抓取任务。
现在,我们已经了解了代码的不足之处,并熟悉了更高效的方法,接下来让我们改写代码,使其更加成功:
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
self.found_links = []
def fetch_page(self, url):
"""下载页面内容。"""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"无法下载 {url}: {e}")
return None
def extract_links(self, url, html):
"""提取并处理页面中的所有链接。"""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
if full_url not in self.visited and full_url not in self.to_visit:
self.found_links.append(full_url)
def process_page(self, url):
"""处理单个页面并收集链接。"""
html = self.fetch_page(url)
if html:
self.extract_links(url, html)
self.visited.add(url)
def crawl(self):
"""从初始 URL 开始抓取网页。"""
with ThreadPoolExecutor(max_workers=10) as executor:
# 将初始 URL 添加到队列中
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
executor.submit(self.process_page, url)
# 等待所有页面处理完成
executor.shutdown(wait=True)
return self.found_links
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
print("找到的链接:")
for link in links:
print(link)我们对爬虫进行了如下改进,以提高其速度和效率:
- 多任务处理:使用 ThreadPoolExecutor 进行并行页面加载,加速执行。
- 立即收集所有链接:所有找到的链接都会保存在 found_links 列表中,并且在所有页面处理完之后显示结果。
- 删除中间输出:去除了每个页面的日志记录,以加速执行。
解释:
- ThreadPoolExecutor 使得多个页面可以并行处理,这显著加快了抓取过程,特别是在页面数量较多时。
- found_links 列表保存了所有在页面上找到的链接,页面处理完毕后这些链接会被输出。
输出示例:
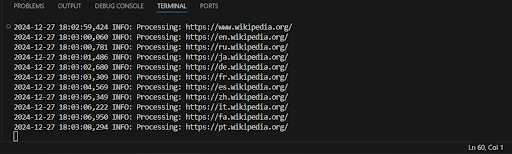
太好了,现在我们的代码运行得更快,并且能立即显示所有找到的链接!
启动网络爬虫后,重要的是要保存收集到的数据。保存找到的链接的最流行和简单的方法之一是使用 JSON 文件格式。JSON 格式轻量、易读,并广泛用于数据交换。让我们看一下如何将找到的链接保存到文件中,并讨论几种实现方法。
以下是如何使用之前代码中的 SimpleCrawler 示例来实现:
import json
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
self.found_links = []
def fetch_page(self, url):
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"无法获取 {url}: {e}")
return None
def extract_links(self, url, html):
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
if full_url not in self.visited and full_url not in self.to_visit:
self.found_links.append(full_url)
def process_page(self, url):
html = self.fetch_page(url)
if html:
self.extract_links(url, html)
self.visited.add(url)
def crawl(self):
with ThreadPoolExecutor(max_workers=10) as executor:
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
executor.submit(self.process_page, url)
executor.shutdown(wait=True)
return self.found_links
def save_to_json(self, filename):
"""将找到的链接保存到 JSON 文件。"""
with open(filename, 'w', encoding='utf-8') as file:
json.dump(self.found_links, file, ensure_ascii=False, indent=4)
logging.info(f"找到的链接已保存到 {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# 将链接保存到 JSON 文件
crawler.save_to_json('found_links.json')
print("找到的链接已保存到 'found_links.json'")运行后,代码会将链接保存到 found_links.json 文件,文件内容大致如下:
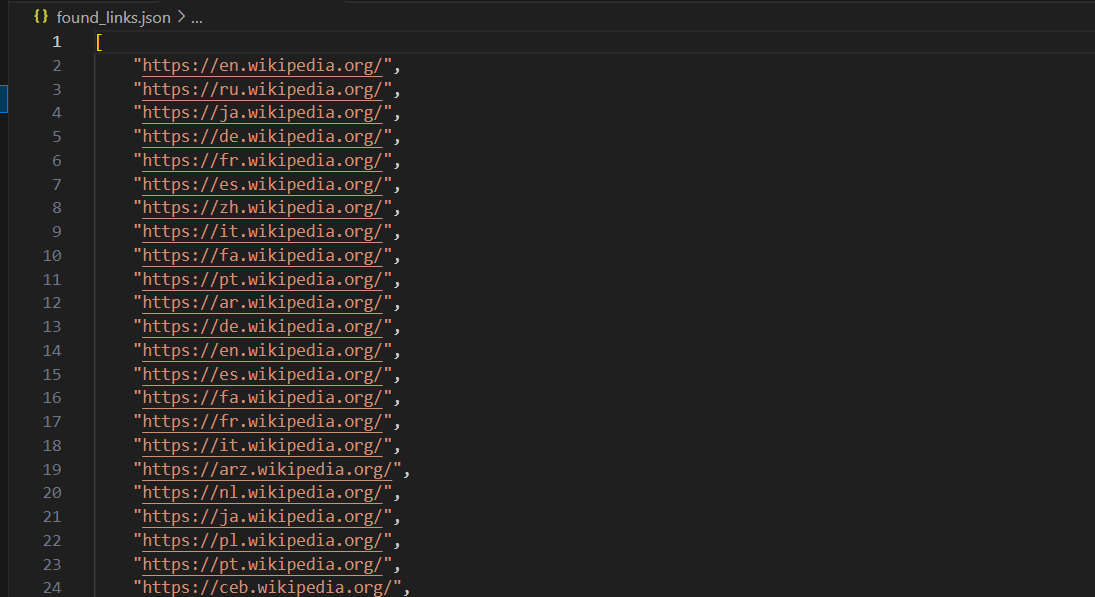
除了将链接保存到 JSON 文件外,还有其他方法可以存储 Web 爬取过程中收集的数据。以下是一些常见的方法:
保存到 CSV 文件
CSV(逗号分隔值)是一种简单且广泛使用的表格数据存储格式。它可以轻松在 Excel 或 Google 表格中打开。
import csv
class SimpleCrawler:
# 之前的代码...
def save_to_csv(self, filename):
"""将找到的链接保存到 CSV 文件。"""
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['URL']) # 列标题
for link in self.found_links:
writer.writerow([link])
logging.info(f"找到的链接已保存到 {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# 将链接保存到 CSV 文件
crawler.save_to_csv('found_links.csv')
print("找到的链接已保存到 'found_links.csv'")保存到数据库(SQLite)
如果希望将链接存储到数据库中,以便更方便地查询,SQLite 是一个不错的选择。它是一种轻量级数据库,不需要单独的服务器,非常适合存储小型和中型数据。
import sqlite3
class SimpleCrawler:
# 之前的代码...
def save_to_database(self, db_name):
"""将找到的链接保存到 SQLite 数据库。"""
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
# 如果表不存在,则创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS links (
id INTEGER PRIMARY KEY AUTOINCREMENT,
url TEXT UNIQUE
)
''')
# 插入每个链接到数据库
for link in self.found_links:
cursor.execute('INSERT OR IGNORE INTO links (url) VALUES (?)', (link,))
conn.commit()
conn.close()
logging.info(f"找到的链接已保存到 {db_name}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# 将链接保存到数据库
crawler.save_to_database('found_links.db')
print("找到的链接已保存到 'found_links.db'")保存到 Excel 文件(XLSX)
如果更喜欢使用 Excel,可以使用 openpyxl 库将数据直接保存到 Excel 文件中。
from openpyxl import Workbook
class SimpleCrawler:
# 之前的代码...
def save_to_excel(self, filename):
"""将找到的链接保存到 Excel 文件。"""
workbook = Workbook()
sheet = workbook.active
sheet.append(['URL']) # 列标题
for link in self.found_links:
sheet.append([link])
workbook.save(filename)
logging.info(f"找到的链接已保存到 {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# 将链接保存到 Excel 文件
crawler.save_to_excel('found_links.xlsx')
print("找到的链接已保存到 'found_links.xlsx'")这些方法可以根据您的具体需求选择最合适的存储方式。
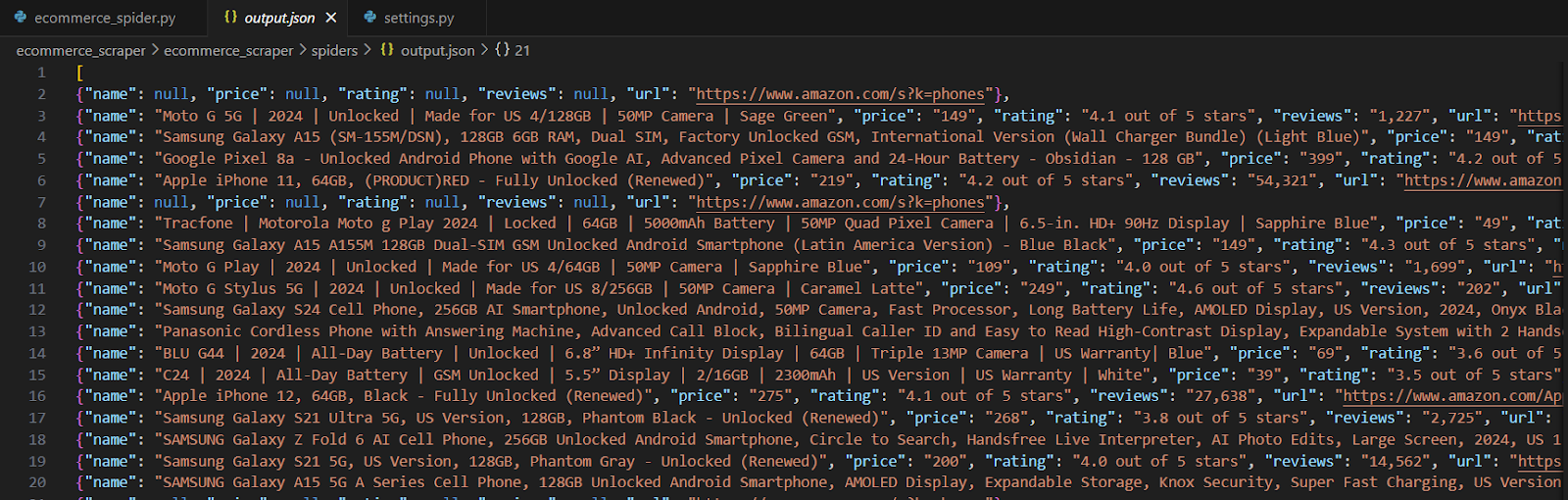
现在,让我们使用 Scrapy 为 Amazon.com 创建一个爬虫(在开始之前,请先阅读 Scrapy 文档)。
步骤 1:打开 Amazon 搜索结果页面
在您的浏览器中打开 Amazon 搜索结果页面,例如:https://www.amazon.com/s?k=phones。
步骤 2:打开开发者工具 (DevTools)
- 右键点击页面的任意部分,然后选择 “Inspect”(检查元素)。
- 或者使用快捷键:
- Windows/Linux: Ctrl + Shift + I
- Mac: Cmd + Option + I
这将打开 DevTools,您可以在其中研究页面的 HTML 结构。
步骤 3:查找需要提取的元素
- 在 Amazon 页面上,将鼠标悬停在产品名称上。
- 在 DevTools 中,相应的 HTML 代码会被高亮显示。
- 右键点击产品名称的 HTML 代码,选择 “Inspect”(检查元素)。
步骤 4:分析 HTML 结构
观察相关的标签和类属性。例如,产品名称可能位于 <a> 标签内的 <span> 标签中,并带有特定的 CSS 类(如 a-text-normal)。
在这种情况下,提取产品名称的 CSS 选择器如下:
a.a-link-normal.s-line-clamp-2.a-text-normal span::text
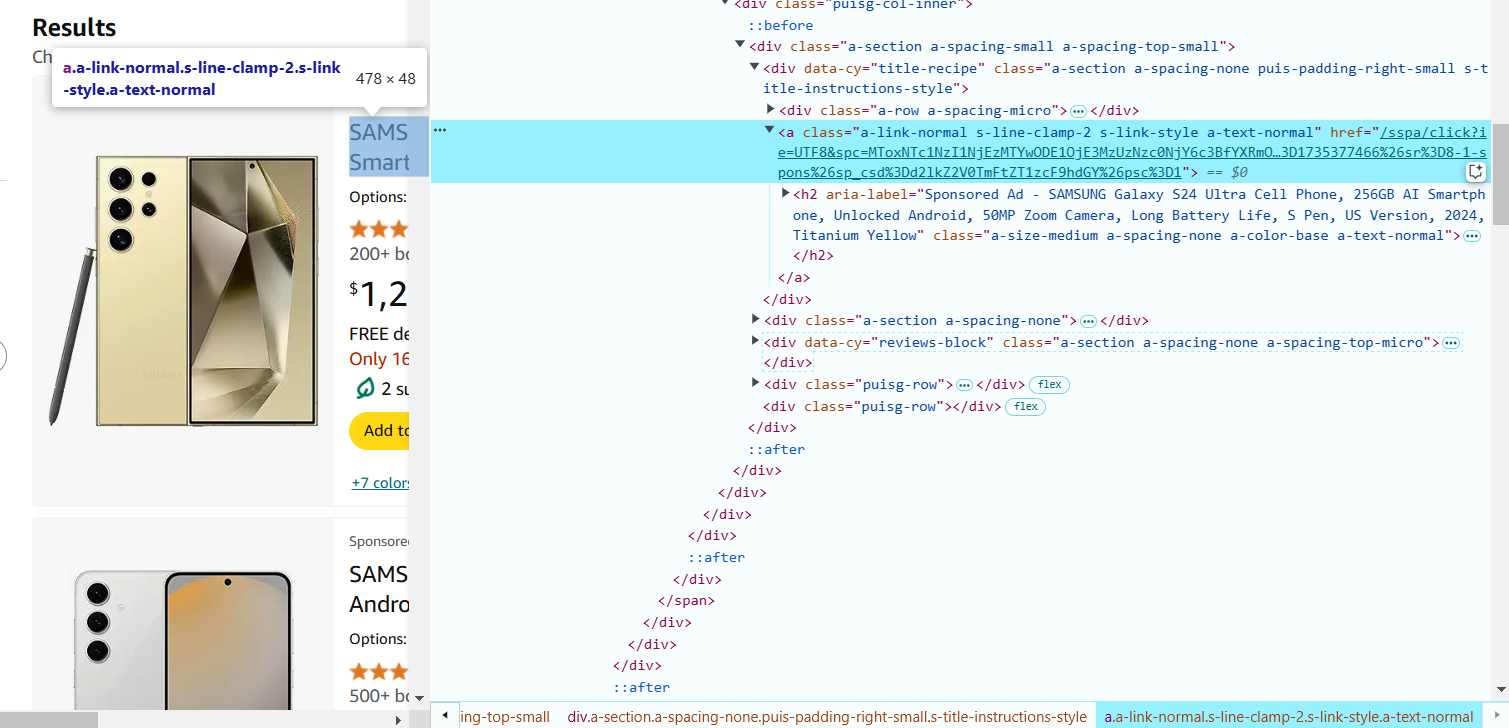
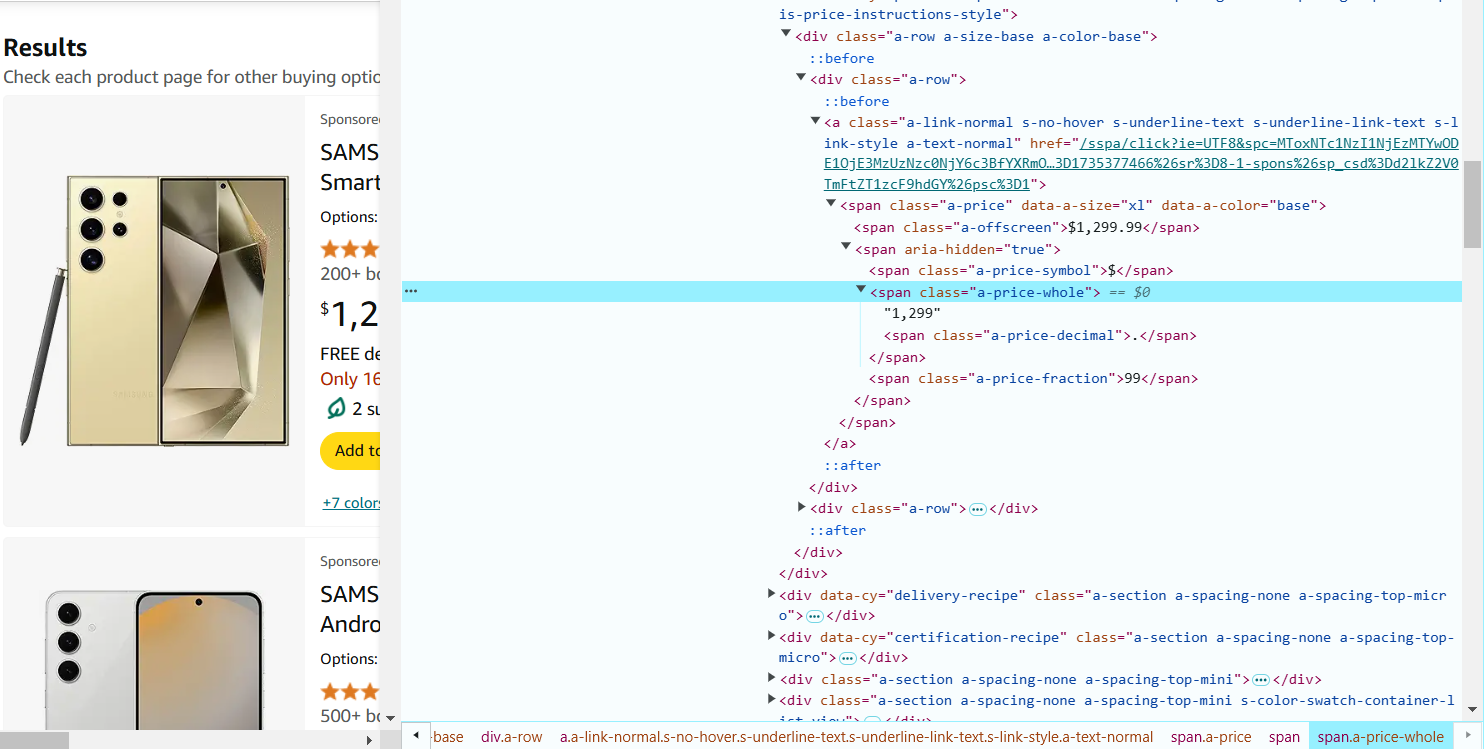
5. 将鼠标悬停在页面上的产品价格上,右键点击并选择 “Inspect”(检查元素)。
价格可能位于 <span> 标签内,并带有类似 a-price-whole 的类名。
提取价格的 CSS 选择器如下:span.a-price-whole::text.
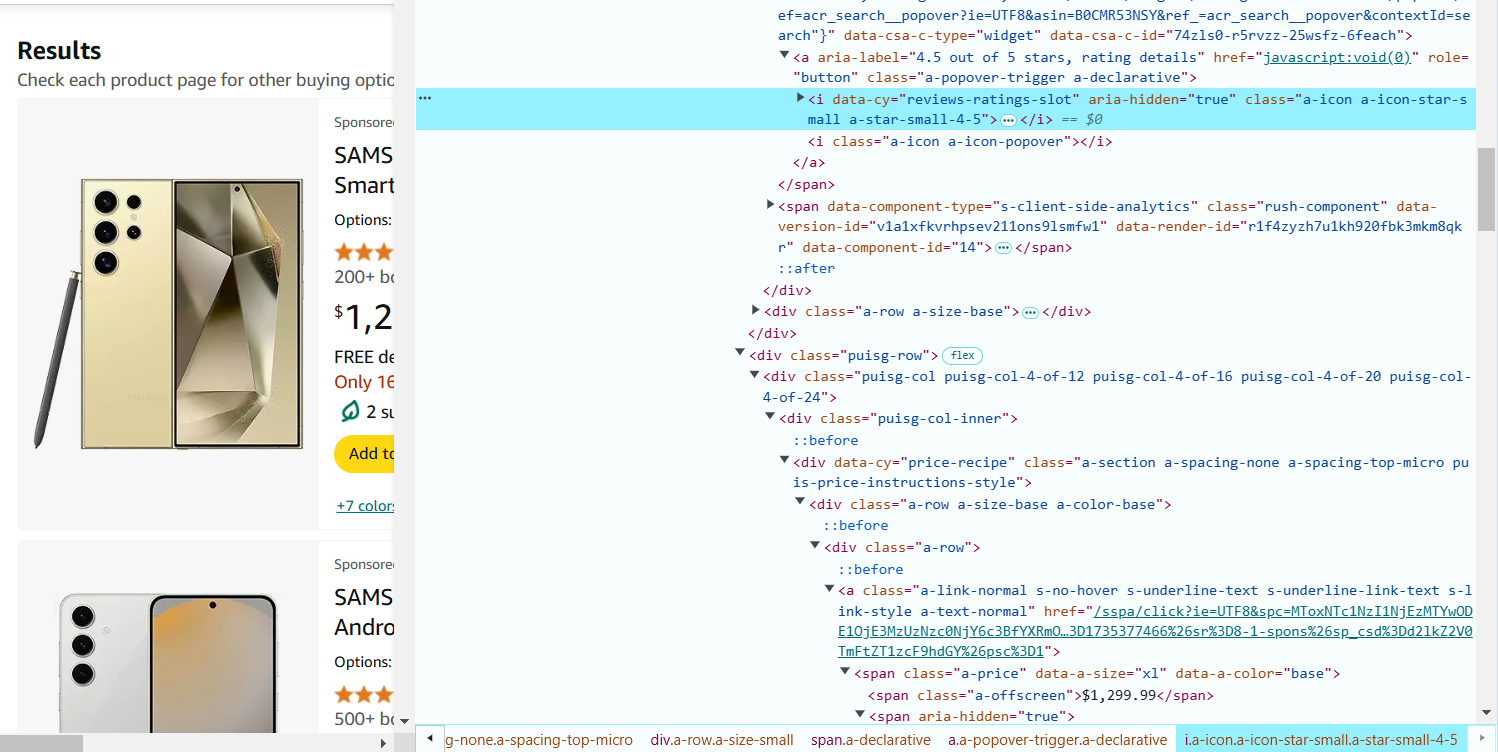
6. 将鼠标悬停在产品评分(星级)上,右键点击并选择 “Inspect”(检查元素)。
评分通常位于 <i> 标签内,并带有类似 a-icon-star-small 的类名。
提取评分的 CSS 选择器如下:i.a-icon-star-small span.a-icon-alt::text
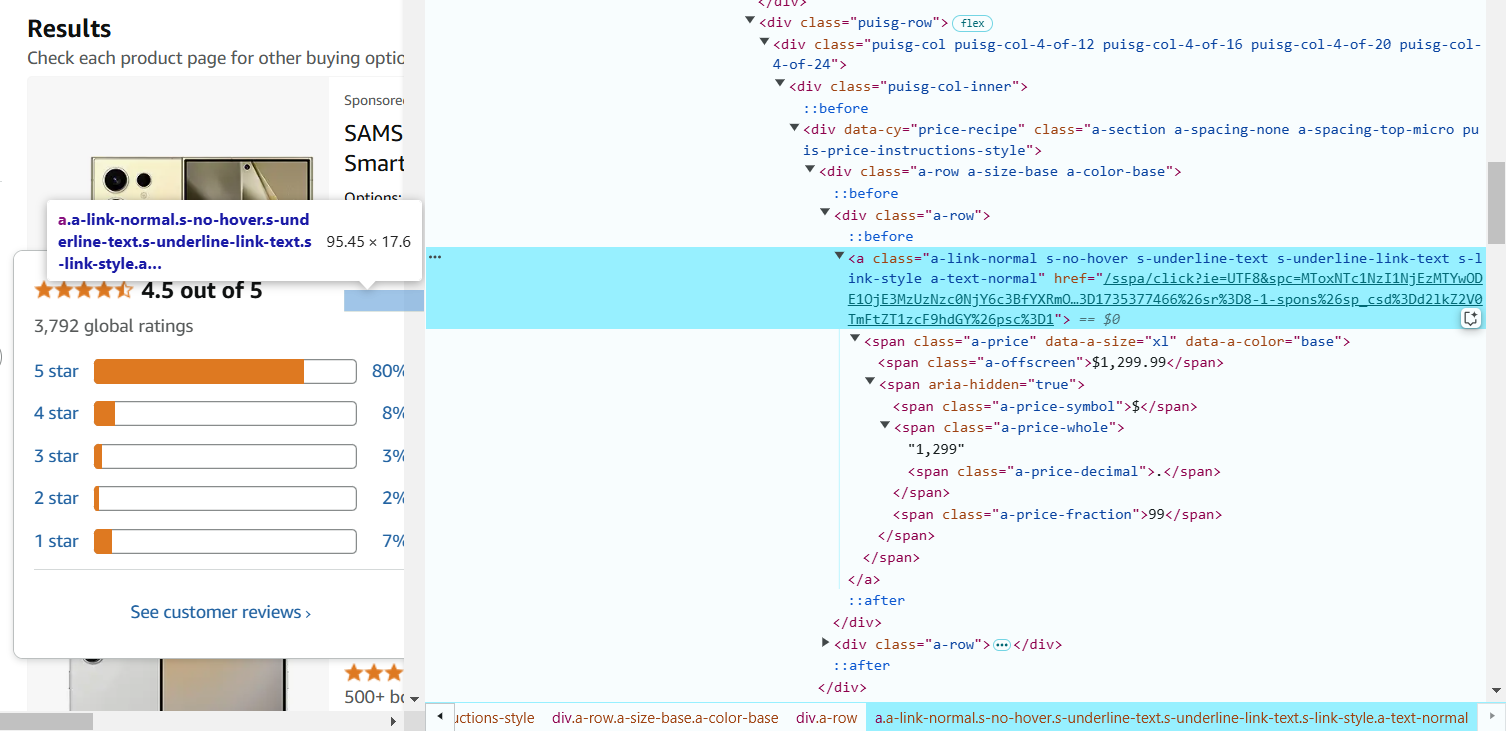
7. 将鼠标悬停在评论数量上,右键点击并选择 “Inspect”(检查元素)。
评论数量通常位于 <span> 标签内,并带有 a-size-base s-underline-text 类名。
提取评论数量的 CSS 选择器如下:span.a-size-base.s-underline-text::text
8. 将鼠标悬停在产品名称上,右键点击并选择 “Inspect”(检查元素)。
链接位于 <a> 标签内,URL 存储在 href 属性中。
提取产品 URL 的 CSS 选择器如下:
a.a-link-normal.s-line-clamp-2.s-link-style::attr(href)
9. 创建 Scrapy 爬虫
现在,您已经找到了必要的 CSS 选择器,可以在 Scrapy 爬虫中使用它们来提取数据。
import scrapy
class AmazonSpider(scrapy.Spider):
name = "ecommerce"
# 起始 URL
start_urls = [
'https://www.amazon.com/s?k=phones'
]
def parse(self, response):
# 记录日志以进行调试
self.log(f"Parsing page: {response.url}")
# 提取产品详细信息
for product in response.css('div.s-main-slot div.s-result-item'):
# 提取产品名称
name = product.css('a.a-link-normal.s-line-clamp-2.a-text-normal span::text').get()
if name: # 检查是否存在产品名称
self.log(f"Found product: {name}")
# 提取价格(某些产品可能没有)
price = product.css('span.a-price-whole::text').get()
# 提取评分(某些产品可能没有)
rating = product.css('i.a-icon-star-small span.a-icon-alt::text').get()
# 提取评论数量
reviews = product.css('span.a-size-base.s-underline-text::text').get()
# 提取产品 URL
product_url = product.css('a.a-link-normal.s-line-clamp-2.s-link-style::attr(href)').get()
yield {
'name': name,
'price': price,
'rating': rating,
'reviews': reviews,
'url': response.urljoin(product_url),
}
# 翻页:进入下一页
next_page = response.css('li.a-last a::attr(href)').get()
if next_page:
self.log(f"Following next page: {next_page}")
yield response.follow(next_page, self.parse)代码解释:
- start_urls: 这是爬虫的起始 URL,本例中是 Amazon 上的手机搜索结果页。
- parse 方法: 用于从 HTML 响应中提取数据,使用 CSS 选择器找到所需元素。
- product.css('selector::text'): 提取符合选择器的元素的文本内容。
- product.css('selector::attr(href)'): 提取 <a> 标签的 href 属性(URL)。
- 分页: 爬虫会根据 next_page 变量中的链接,自动翻页抓取所有商品数据。
10. 运行爬虫
创建爬虫后,将文件保存到 Scrapy 项目的 spiders 目录中(例如 amazon_spider.py)。
运行以下命令启动爬虫,并将数据保存到 JSON 文件中:
scrapy crawl ecommerce -o products.json
生成的 JSON 文件将包含类似以下格式的提取信息:
重要注意事项
真实的电商网站(如 Amazon、eBay 等)通常具有复杂的反爬机制,包括 CAPTCHA、请求频率限制和动态内容。为了成功爬取这些网站,必须考虑这些因素。
- 遵守 robots.txt 规则:在爬取任何网站之前,请检查其 robots.txt 文件,并确保您的爬取行为符合其爬取政策。应当以合乎道德的方式进行数据采集,遵守网站的使用条款,避免对服务器造成过载请求。此外,确保所收集的数据符合隐私法规(如 GDPR)。
- 绕过反爬机制:许多网站使用 reCAPTCHA、DataDome 或 Cloudflare 来防止自动化爬取。在遇到 CAPTCHA 时,可以集成 CapMonster Cloud 等工具来自动解决验证码。CapMonster Cloud 提供 API 来处理各种验证码,包括 Google reCAPTCHA、Geetest 等。
- 伪装浏览器指纹:网站可能会通过分析浏览器指纹(如 User-Agent、Accept-Language 以及其他请求头)来检测爬虫。因此,建议定期更改这些指纹(例如,使用 BrowserStack 或 ProxyCrawl 之类的工具),或者手动设置自定义请求头和动态代理。
使用 IP 轮换和代理服务:为了避免因高频请求被封禁,可以使用 IP 轮换技术。例如,借助 ScraperAPI 或 ProxyMesh 等代理服务,使每个请求来自不同的 IP 地址,以减少被检测到的风险。
以下是使用 Playwright 进行动态网页爬取的示例。本脚本从 Hacker News (https://news.ycombinator.com/) 提取最新新闻。该网站使用 JavaScript 动态加载内容,因此普通爬虫无法直接获取所有数据。
为什么使用 Playwright?
此方法适用于那些 不会立即显示完整内容 的网站(例如,使用 JavaScript 加载数据的站点)。Playwright 允许爬虫像真实用户一样 等待网页加载完成,然后再提取数据,非常适合现代动态网站!
- 安装 Playwright
如果尚未安装,请在终端执行以下命令:
pip install playwright
playwright install如果只想安装 Chromium 浏览器:
pip install playwright
playwright install chromium- 代码示例
from playwright.sync_api import sync_playwright
def dynamic_crawler():
with sync_playwright() as p:
# 启动 Chromium 浏览器(无头模式)
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# 访问目标网站
url = "https://news.ycombinator.com/"
page.goto(url)
# 等待新闻内容加载
page.wait_for_selector(".athing")
# 提取数据
articles = []
for item in page.query_selector_all(".athing"):
title = item.query_selector(".titleline a").inner_text()
link = item.query_selector(".titleline a").get_attribute("href")
rank = item.query_selector(".rank").inner_text() if item.query_selector(".rank") else None
articles.append({"rank": rank, "title": title, "link": link})
# 关闭浏览器
browser.close()
# 打印结果
for article in articles:
print(article)
# 运行爬虫
dynamic_crawler()代码解析
- 启动浏览器:
chromium.launch(headless=True) 启动一个无头浏览器(headless 模式不会弹出浏览器窗口)。 - 访问目标网站:
page.goto(url) 让 Playwright 进入 Hacker News 首页。 - 等待内容加载:
page.wait_for_selector(".athing") 等待新闻列表加载,确保数据已经出现。 - 提取数据:
page.query_selector_all(".athing") 找到所有新闻条目。
.titleline a 获取标题。
.titleline a::attr(href) 获取新闻链接。
.rank 获取排名(部分新闻没有排名)。
- 关闭浏览器:
数据采集完毕后,browser.close() 关闭浏览器,释放资源。 - 输出结果:
脚本会打印每条新闻,包括 排名、标题和链接。
示例输出
运行爬虫后,终端会输出类似以下的内容:
{'rank': '1.', 'title': '一个很棒的开源项目', 'link': 'https://example.com'}
{'rank': '2.', 'title': '如何学习 Python', 'link': 'https://news.ycombinator.com/item?id=123456'}
{'rank': '3.', 'title': 'Show HN: 我的新工具', 'link': 'https://example.com/tool'}使用 Python 进行网页爬取是从网站收集数据并发现有价值的见解的好方法。通过使用 BeautifulSoup、Scrapy 和 Playwright 等工具,您可以处理简单的静态网站以及更复杂的动态网站。我们讨论的示例展示了如何提取数据以及如何处理诸如 JavaScript 内容和网站限制等问题。
如果需要绕过封锁,使用代理服务器或解决 CAPTCHA 等方法可能会有所帮助,但重要的是要以道德的方式使用这些方法。
借助 Python 和合适的工具,网页爬取变得既有趣又强大。无论您是刚开始学习还是已经有一些经验,都可以取得良好的成果,让您的项目更加出色。祝您好运,并享受爬取过程!
