Сегодня важность информации достигла своего пика, и умение извлекать и анализировать данные с интернет-ресурсов стало очень важным и востребованным. В данной статье мы рассмотрим основы веб-скрапинга с применением Python и Selenium, а также обсудим, как технология CapMonster Cloud помогает преодолевать сложности с разными капчами. Вы узнаете, как эти инструменты могут значительно улучшить вашу способность получать и обрабатывать данные из интернета, открывая новые горизонты для исследований, анализа данных и автоматизации процессов.
Начните сейчас и автоматизируйте решение reCAPTCHA v2
Веб-скрапинг (web scraping) – это процесс извлечения данных с веб-страниц. Процесс этот обычно включает использование программы или скриптов, получающих представленную на веб-сайтах информацию, которая может быть использована в различных областях и для различных целей. Например, для сравнения цен и услуг конкурентов, анализа потребительских предпочтений, мониторинга разных новостей и событий и многого другого.
Этапы работы веб-скрапинга включают:
Определение целей: на первом этапе необходимо понять, какую информацию нужно извлечь и на каких на веб-ресурсах.
Анализ структуры целевой веб-страницы: изучение HTML-кода страниц, чтобы понять, где и как хранится нужная информация. Поиск и определение элементов, таких, как теги, ID, классы и др.
Разработка скрипта для получения данных: написание кода (например, на языке Python с использованием библиотеки для автоматизации действий в браузере Selenium), который будет посещать веб-страницы, извлекать нужные данные и сохранять их в структурированном виде.
Обработка данных: извлечённые данные часто требуют преобразования для дальнейшего использования. Это может включать удаление дубликатов, исправление форматов, фильтрацию ненужных данных и т.д.
Сохранение данных: сохранение извлечённых и обработанных данных в удобном формате, например, в виде CSV, JSON, базы данных и т.д.
Также важно следить за изменениями на целевом сайте, чтобы своевременно обновлять скрипт в случае необходимости.
Работа с Python и Selenium
Почему Python и Selenium удобны для веб-скрапинга?
Язык программирования Python и библиотеку Selenium часто используют для веб-скрапинга по следующим причинам:
Лёгкость использования: Python прост в использовании и имеет множество библиотек для веб-скрапинга.
Эмуляция действий, доступ к динамическому контенту: с помощью Selenium можно автоматизировать действия пользователя в веб-браузере, включая эмуляцию прокрутки страницы и нажатия кнопок, необходимых для загрузки данных.
Обход антикраулеров: на некоторых сайтах применяются специальные защитные механизмы, и использование эмуляции действий реального пользователя помогает обойти эти механизмы.
Широкая поддержка: большое сообщество и множество ресурсов облегчают работу с этими инструментами.
Если на вашем компьютере ещё не установлен Python, перейдите на официальный сайт Python и скачайте подходящую версию для вашей операционной системы (Windows, macOS, Linux). В терминале удобной для вас среды разработки можете проверить версию Python следующей командой:
python --version
Далее необходимо установить Selenium, выполнив команду:
pip install selenium
Создайте новый файл и импортируйте необходимые библиотеки:
import time
from selenium import webdriver
Также необходимо добавить в проект класс ‘By’, он понадобится нам для определения стратегий поиска элементов на веб-странице в Selenium:
from selenium.webdriver.common.by import By
Параметры драйвера Chrome
Опции ChromeDriver (ChromeOptions) нужны для настройки поведения и параметров запуска браузера Chrome при автоматизации с помощью Selenium. Вот некоторые из этих опций:
--headless: запускает Chrome без графического интерфейса
--disable-gpu: отключает использование GPU. Часто используется с --headless для предотвращения ошибок, связанных с рендерингом графики
В Selenium поиск элементов на веб-странице осуществляется с помощью различных методов, предоставляемых классом By. Эти методы позволяют находить элементы по различным критериям, например, идентификатор элемента (ID), имя класса (class name), имя тега (tag name), имя атрибута (name), текст ссылки (link text)), XPath или CSS-селектор.
Пример поиска по ID:
element = driver.find_element(By.ID, 'element_id')
По имени класса:
element = driver.find_element(By.CLASS_NAME, 'class_name')
По имени тега:
element = driver.find_element(By.TAG_NAME, 'tag_name')
По имени атрибута:
element = driver.find_element(By.NAME, 'element_name')
По тексту ссылки:
element = driver.find_element(By.LINK_TEXT, 'link_text')
По CSS-селектору:
element = driver.find_element(By.CSS_SELECTOR, 'css_selector')
По XPath:
element = driver.find_element(By.XPATH, '//tag[@attribute="value"]')
Если необходимо найти несколько элементов, вместо find_element используется метод find_elements.
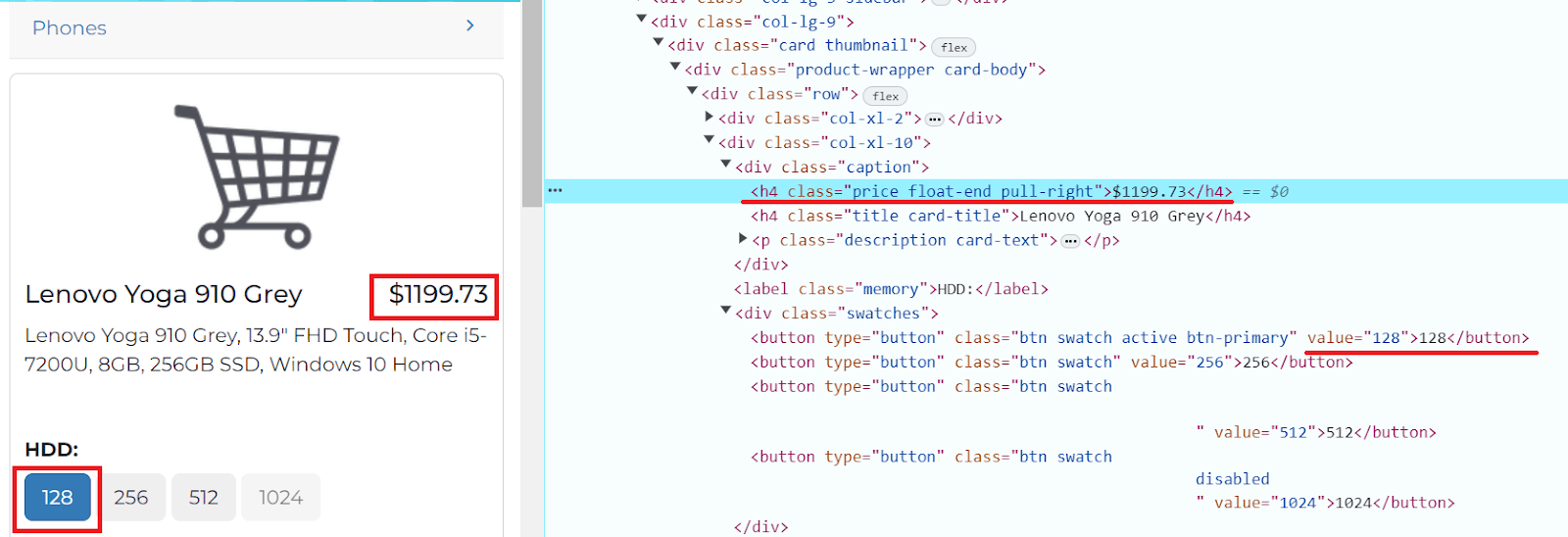
В нашем примере необходимо найти расположение элемента кнопки “128” и информации о цене:
Имитация действий пользователя
В Selenium имитация действий на веб-странице осуществляется с помощью методов, предоставляемых объектом WebElement. Эти методы позволяют взаимодействовать с элементами на странице так, как это делает пользователь: кликать, вводить текст и т.д.
Вот несколько таких методов:
element.click() - клик на элемент
element.send_keys('текст для ввода') - ввод текста в элемент (поле ввода)
element.location_once_scrolled_into_view - прокрутка к элементу
submit() - отправка формы
Вернёмся к нашему примеру. С помощью XPath осуществляется поиск нужной кнопки, после чего нужно сделать клик по ней и найти элемент с ценой:
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button 128.click()
# Ждём некоторое время для загрузки цены
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
Теперь остаётся вывести цену товара с нужным объёмом HDD в консоль:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
price_text = price_element.text
print("Цена товара:", price_text)
driver.quit()
Всплывающие баннеры и окна
Очень часто на сайтах появляются различные баннеры и всплывающие окна, которые могут помешать выполнению скрипта. В таких случаях можно настроить параметры ChromeDriver таким образом, чтобы отключить эти элементы. Вот некоторые из таких параметров:
--disable-notifications: отключает все уведомления
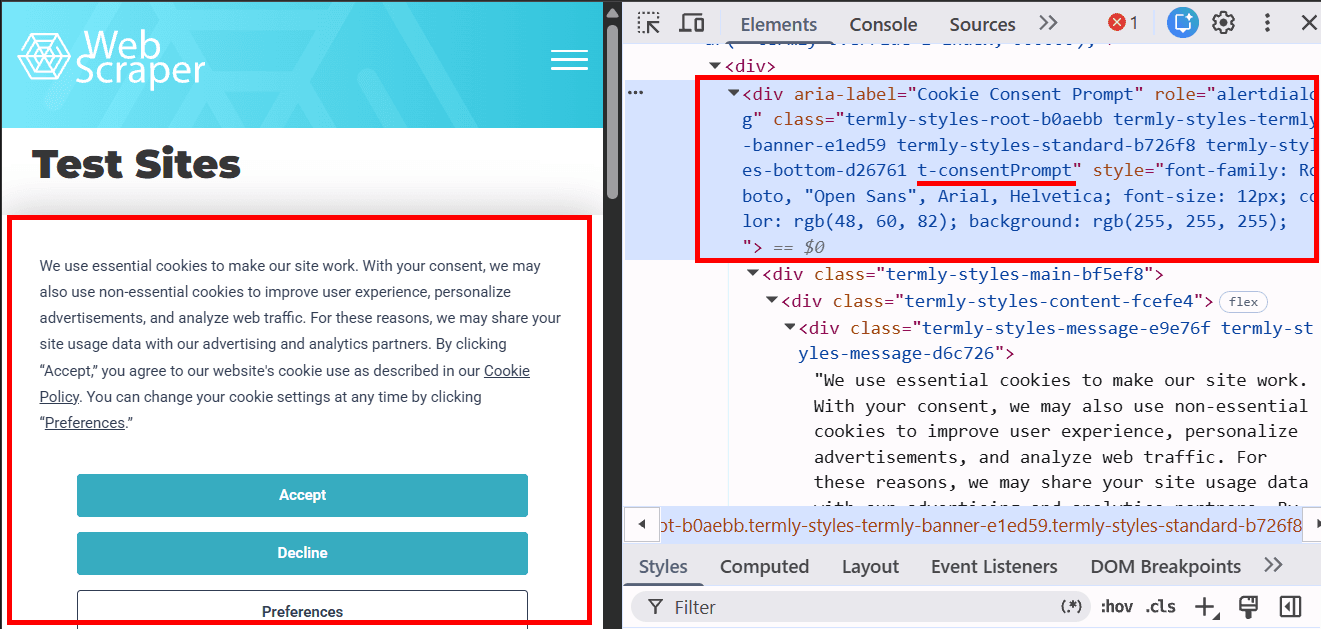
На сайте, который мы используем в нашем примере, при загрузке страницы появляется куки-баннер. Можно также попробовать убрать его другими способами, один из которых – использование отдельного скрипта, который блокирует такие уведомления. Для начала изучим этот элемент c помощью Инструментов разработчика:
Мы будем использовать класс .t-consentPrompt для поиска cookie-баннера, потому что это наиболее стабильный и читаемый CSS-класс элемента. Сгенерированные классы вроде termly-styles-root-b0aebb могут изменяться после обновлений сайта, поэтому их обычно не используют для автоматизации.
Баннер скроем через style.display = 'none', чтобы он не перекрывал страницу и не мешал Selenium взаимодействовать с элементами сайта.
Теперь можем скрыть этот баннер, добавив соответствующую логику в наш скрипт:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
# Скрипт для скрытия cookie-баннера Termly
script = """
var banner = document.querySelector('.t-consentPrompt');
if (banner) {
banner.style.display = 'none';
}
"""
driver.execute_script(script)
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
price_text = price_element.text
print("Цена товара:", price_text)
driver.quit()
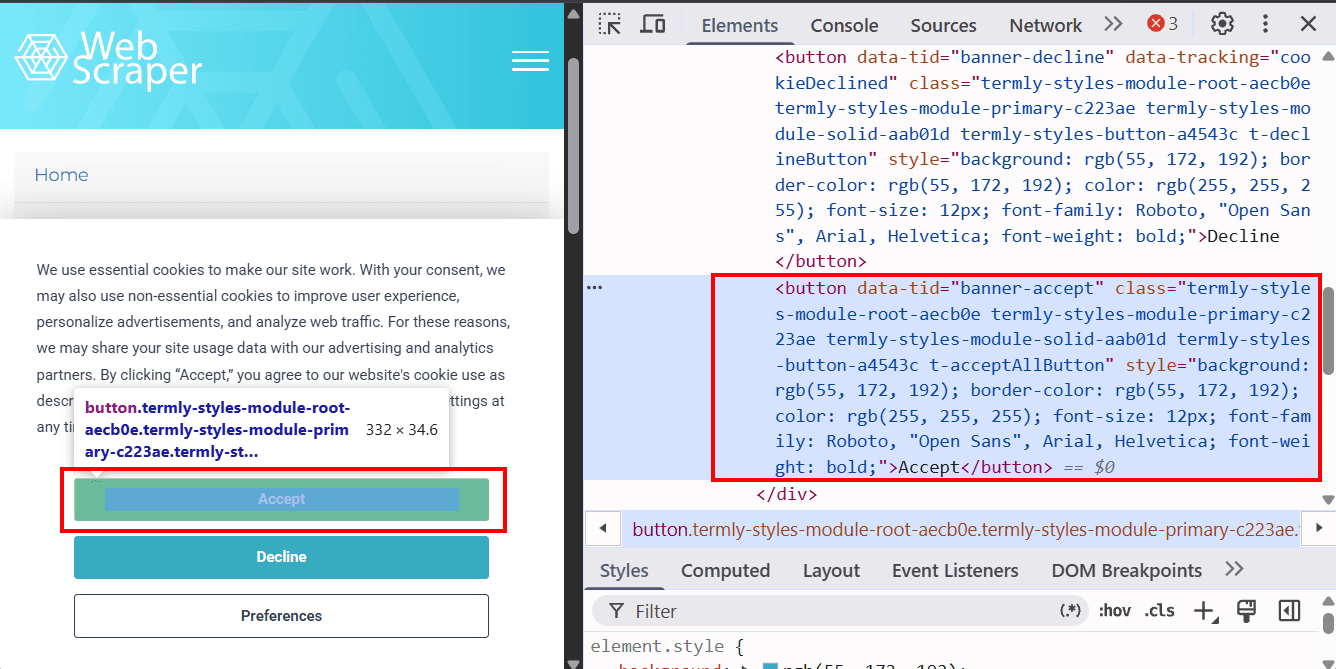
Другим способом закрыть баннер является имитация действия пользователя нажатием кнопок Accept или Decline. Изучите нужный элемент (например, кнопку Accept):
Мы можем найти кнопку по data-tid="banner-accept"и сделать клик по ней с помощью button.click():
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
# Ожидание кнопки Accept и клик по ней
accept_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(
(By.XPATH, "//button[@data-tid='banner-accept']")
)
)
accept_button.click()
# Клик по кнопке 128 GB
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
# Получение цены
price_element = driver.find_element(
By.XPATH,
"//h4[@class='price float-end pull-right']"
)
price_text = price_element.text
print("Цена товара:", price_text)
driver.quit()
Ещё одним из эффективных способов является использование Chrome расширений, которые автоматически принимают или блокируют все баннеры с куки. Эти расширения можно установить в браузере, а затем подключить их в ChromeOptions. Скачайте подходящее расширение в формате .crx. Используйте его в вашем скрипте:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# Путь к расширению .crx
extension_path = '/path/to/extension.crx'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--incognito')
# Добавляем расширение
chrome_options.add_extension(extension_path)
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://webscraper.io/test-sites/e-commerce/allinone/product/123')
button_128 = driver.find_element(By.XPATH, "//button[@value='128']")
button_128.click()
time.sleep(3)
price_element = driver.find_element(By.XPATH, "//h4[@class='price float-end pull-right']")
price_text = price_element.text
print("Цена товара:", price_text)
driver.quit()
Этот подход избавит вас от необходимости вручную взаимодействовать с подобными элементами при загрузке страницы.
Решение капчи при веб-скрапинге
Часто при извлечении данных возникают препятствия в виде капчи, предназначенной для защиты от ботов. Для обхода таких ограничений наиболее эффективны специализированные сервисы, распознающие различные виды капч. Одним из таких инструментов является CapMonster Cloud, который в кратчайшие сроки способен автоматически решать даже самые сложные капчи. Этот сервис предлагает как браузерные расширения (для Chrome, для Firefox), так и API-методы (с ними можете ознакомиться в документации), которые вы можете интегрировать в свой код для получения токенов, успешного обхода защиты и продолжения работы вашего скрипта.
Некоторые типы капч, с которыми легко справляется CapMonster Cloud:
Все виды reCAPTCHA
GeeTest
Cloudflare Turnstile и Challenge
DataDome
Пример кода для автоматического решения капчи и веб-скрапинга
Этот скрипт использует официальную Python-библиотеку CapMonster Cloud и Selenium для решения капчи на странице, после чего извлекает заголовок этой страницы и выводит его в консоль:
import asyncio
from selenium import webdriver
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from capmonstercloudclient import CapMonsterClient, ClientOptions
from capmonstercloudclient.requests import RecaptchaV2Request
async def solve_captcha(api_key, page_url, site_key):
client_options = ClientOptions(api_key=api_key)
cap_monster_client = CapMonsterClient(options=client_options)
recaptcha2request = RecaptchaV2Request(websiteUrl=page_url, websiteKey=site_key)
responses = await cap_monster_client.solve_captcha(recaptcha2request)
return responses['gRecaptchaResponse']
async def parse_site_title(driver: WebDriver, url: str) -> str:
driver.get(url)
driver.implicitly_wait(10)
title_element = driver.find_element(By.TAG_NAME, 'title')
title = title_element.get_attribute('textContent')
return title
async def main():
api_key = 'YOUR_API_KEY' # Замените на ваш API-ключ от CapMonsterCloud
page_url = 'https://lessons.zennolab.com/captchas/recaptcha/v2_simple.php?level=low'
site_key = '6Lcf7CMUAAAAAKzapHq7Hu32FmtLHipEUWDFAQPY'
options = Options()
driver = webdriver.Chrome(options=options)
captcha_response = await solve_captcha(api_key, page_url, site_key)
print("Решение капчи:", captcha_response)
site_title = await parse_site_title(driver, page_url)
print("Заголовок страницы:", site_title)
driver.quit()
if __name__ == "__main__":
asyncio.run(main())
Заключение
Использование Python и Selenium для веб-скрапинга открывает множество возможностей для автоматизации сбора данных с веб-сайтов, а интеграция с CapMonster Cloud помогает легко обходить капчи и значительно упрощает процесс сбора информации. Эти инструменты позволяют не только ускорить работу, но и обеспечить точность и надёжность получаемых данных. С их помощью вы можете собирать данные из самых разных источников, от интернет-магазинов до новостных сайтов, и использовать их для анализа, исследований или создания собственных проектов. И при всём этом необязательно иметь углублённые знания программирования, — современные технологии делают веб-скрапинг доступным даже для новичков. Так что, если для Вас важны простота, максимальное удобство и экономия времени в работе с данными, Python, Selenium и CapMonster Cloud — отличное сочетание для достижения этой цели!
NB: Пожалуйста, обратите внимание, что продукт предназначен для автоматизации тестирования исключительно ваших собственных веб-сайтов и ресурсов, к которым у вас есть законное право доступа.
Узнайте, как эффективно собирать данные об e-commerce с сайтов — от цен и остатков до отзывов и фото товаров. В этой статье разберем продемонстрируем пошаговый процесс и методы автоматизации при помощи CapMonster Cloud.