
10 лучших инструментов веб-скрейпинга для извлечения контента с нескольких сайтов одновременно
В прошлом квартале наша команда попыталась собрать данные о продуктах с 38 нишевых интернет-магазинов для рыночного анализа. Скрапер, который мы создали для первого сайта, продержался примерно на трёх. К седьмому сайту он уже ломался в четырёх разных местах.
Именно этот пробел закрывает данное руководство. Выбор подходящих инструментов веб-скрейпинга, когда вы одновременно скрейпите множество сайтов, — совершенно другая задача, чем скрейпинг одного. Один сайт можно привести в порядок силой. Сорок сайтов с разной вёрсткой, разными антибот-стеками и разными сценариями входа «съедят» любой инструмент, который не был создан для такой работы.
Мы протестировали и сравнили 10 лучших инструментов веб-скрейпинга, доступных в 2026 году — от AI-расширений для Chrome до корпоративных scraping API — и ранжировали их по тому, насколько хорошо они выдерживают нагрузку на множестве сайтов. Вы получите честные плюсы и минусы, актуальные цены и чёткое понимание того, какой веб-скрапер подходит под ваш сценарий.
Почему мультисайтовый веб-скрейпинг сложнее, чем извлечение с одной страницы?
Мультисайтовый скрейпинг сложнее, потому что каждый сайт — отдельный микропроект. Разная HTML-структура, разные схемы пагинации, разные антибот-стеки и разные барьеры входа быстро накапливаются, когда вы обрабатываете десятки целей в одном пайплайне.
На практике это усложняют три вещи:
- Разброс вёрстки. Селектор, который работает на сайте A, ломается на сайте B. Чем больше сайтов в охвате, тем больше поломок.
- Разнообразие антибот-защиты. Один сайт использует Cloudflare Turnstile, другой — DataDome, третий — reCAPTCHA Enterprise. У каждого свой сценарий прохождения проверки.
- Объём и лимиты запросов. На множестве сайтов вы чаще упираетесь в rate limits, фингерпринтинг и поведенческие проверки, чем при скрейпинге одной цели.
Масштаб автоматизированного трафика показывает, насколько бдительными стали сайты. Согласно отчёту Imperva Bad Bot Report 2025, автоматизированный трафик впервые за десятилетие превысил трафик, созданный людьми, и составил 51% всего веб-трафика в 2024 году. В том же отчёте отмечается, что Imperva заблокировала 13 триллионов запросов вредоносных ботов на тысячах доменов за прошлый год. Каждый сайт, который вы скрейпите, настороже.
Между тем спрос на эти данные продолжает расти. Mordor Intelligence выяснила, что 65% предприятий использовали веб-скрейпинг для проектов ИИ и машинного обучения в 2024 году. Войны цен в реальном времени подтолкнули 81% американских ритейлеров к автоматизированному скрейпингу цен для динамического репрайсинга — по сравнению с 34% в 2020 году.
Команды, которые масштабируют сбор данных, выигрывают. Те, кто не может, теряют позиции. Правильный инструмент определяет, в какую группу вы попадёте.
На что обращать внимание в инструментах веб-скрейпинга, которые извлекают контент с нескольких сайтов?
Лучшие инструменты веб-скрейпинга для извлечения контента с нескольких сайтов объединяют пять черт: гибкость к вёрстке, обработку пагинации, устойчивость к антибот-защите, чистый структурированный вывод и переиспользуемые задачи. Упустите любую из них — и вы будете тратить больше времени на починку сломанных скраперов, чем на анализ данных.
Вот практический чеклист, который мы использовали для ранжирования инструментов ниже.
Несколько неочевидных моментов, на которые стоит обратить внимание:
- Код или no-code — реальный развилка. Визуальные скраперы вроде Octoparse или ParseHub экономят недели настройки, но упираются в потолок на высокодинамичных сайтах. Фреймворки на коде вроде Scrapy или Playwright справляются с чем угодно, но требуют инженерного времени.
- ИИ изменил отрасль. Современные AI-скраперы читают страницу семантически. Они понимают, что означает «цена» или «отзыв», без жёстко заданного селектора — и это обобщается на разные сайты так, как шаблонные скраперы не могут.
- CAPTCHA — неизбежная статья расходов. Чем больше сайтов вы обходите, тем больше CAPTCHA вы увидите. Заложите это заранее с выделенным решателем, а не прикручивайте его после того, как пайплайн начнёт падать.
Какие 10 лучших инструментов веб-скрейпинга для мультисайтовых данных в 2026 году?
10 лучших инструментов веб-скрейпинга для мультисайтового извлечения данных в 2026 году — Chat4Data, Octoparse, Apify, Bright Data, ScrapingBee, Browse.ai, ParseHub, Zyte, Scrapy и Playwright. Каждый подходит под разную комбинацию масштаба, технической подготовки и бюджета.
Вот сводная таблица, прежде чем мы углубимся в детали.
Теперь сами обзоры.
1. Chat4Data: AI-скрейпинг на простом английском на разных сайтах
Chat4Data — это AI веб-скрапер, работающий как расширение Chrome. Откройте любую публичную веб-страницу, напишите на простом английском, что вам нужно («get product name, brand, rating, review count, and price for the top 50 Lego results on Amazon»), и агент покажет пошаговый план перед запуском. Просмотрите план, нажмите start — и данные экспортируются в Excel, CSV или JSON.
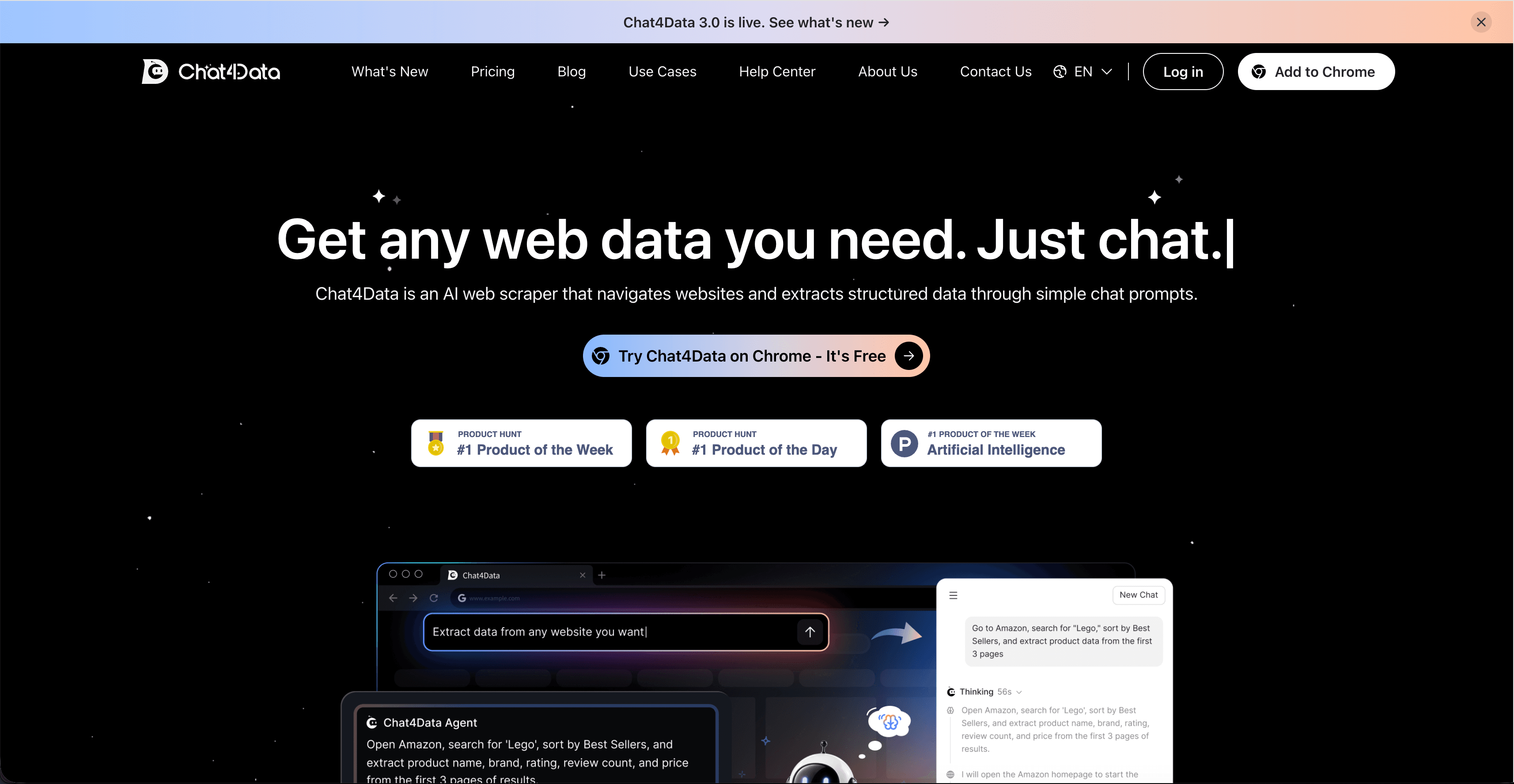
Chat4Data подходит для мультисайтового сценария тем, что тот же интерфейс на простом английском работает независимо от вёрстки сайта. Не нужно поддерживать шаблоны для каждого сайта. В каталоге недвижимости запросите address, price, beds, and agent contact. На сайте сравнения SaaS запросите the vendor name, pricing tier, and key features. Тот же workflow, разные сайты.
При первом запуске, скрейпя сайт сравнения SaaS, я запросил pricing tier, key features, and vendor name. Агент чисто взял pricing tier и vendor, но пропустил две функции, спрятанные в свёрнутом аккордеоне. Я уточнил промпт, добавив "including features hidden under 'Show more' toggles", и перезапустил. Второй проход — полный. Предпросмотр плана упростил исправление: я видел, какие шаги агент пропускает.
Тип: AI-агент веб-скрейпинга (расширение Chrome).
Лучше всего для: Нетехнических пользователей, включая продавцов, маркетологов и исследователей, которым нужны чистые данные с множества публичных страниц без написания кода.
Ключевые возможности:
- Промпты на простом английском, без селекторов и шаблонов;
- Извлечение всей страницы в одной задаче (title, price, specs, reviews вместе);
- Предпросмотр плана перед запуском — вы видите, что сделает агент;
- Приостанавливается для входа и CAPTCHA, затем продолжает;
- Пагинация, бесконечная прокрутка и обработка детальных страниц — автоматически;
- Настроить один раз, перезапустить позже. Повторные скрейпы не расходуют кредиты;
- Экспорт в Excel, CSV, JSON.
Плюсы: Самый быстрый путь от идеи к данным для нетехнических пользователей. Тот же workflow обрабатывает совершенно разные сайты. Честный охват: создан для пакетов до десятков тысяч записей, что покрывает большинство реальных задач lead-gen, e-commerce и исследований.
Минусы: Первоначальная AI-настройка расходует кредиты на каждой новой странице. Работает в активной вкладке Chrome, поэтому очень крупные промышленные пайплайны на миллионы записей — на другом стеке.
Цены: Бесплатный план с 300 приветственными кредитами; Pro, $10/месяц с 2 000 ежемесячными кредитами; Max, $35/месяц с 8 000 кредитами. Годовая оплата экономит 30%. Chat4Data можно скачать в Chrome Web Store.
2. Octoparse: шаблоны, которые масштабируются на похожие сайты
Octoparse — no-code визуальный инструмент веб-скрейпинга с 600+ готовыми шаблонами для популярных сайтов и функцией AI auto-detect, которая собирает рабочий скрапер менее чем за 30 секунд на большинстве стандартных страниц. Это рабочая лошадка, когда вы скрейпите один и тот же тип данных с множества похожих сайтов: десять разных маркетплейсов недвижимости или пятнадцать нишевых интернет-магазинов со схожей вёрсткой.
Меня удивило, сколько тяжёлой работы auto-detect сделал с первой попытки. На странице категории e-commerce с 48 товарами он подхватил нужные поля (name, price, rating, URL) с первого прохода и обработал пагинацию без моего вмешательства. Octoparse силён в повторяющихся мультисайтовых задачах, потому что шаблоны переиспользуемы, а облачная версия работает круглосуточно со встроенной ротацией IP. Скрапер для сайта A можно клонировать и отредактировать для сайта B за минуты, когда вёрстки похожи.
Тип: No-code визуальный скрапер (desktop + cloud).
Лучше всего для: Повторяющегося извлечения данных с множества сайтов со схожей вёрсткой (e-commerce, недвижимость, job boards, каталоги).
Ключевые возможности:
- 600+ готовых шаблонов для распространённых сайтов;
- AI auto-detect собирает скраперы без ручного выбора полей;
- Облачное планирование, ротация IP, решение CAPTCHA;
- Параллельные облачные запуски для одновременного скрейпинга;
- Экспорт в Excel, CSV, JSON, Google Sheets и базы данных.
Плюсы: Зрелый, стабильный, используется 3M+ людьми. Бесплатный план щедрый (10 задач, 50K записей/месяц). Шаблоны радикально сокращают время настройки.
Минусы: Сложности с очень динамичными JavaScript-сайтами. Дополнительные расходы (residential proxies по $3/GB, кредиты CAPTCHA) раздувают счёт на масштабе.
Цены: Бесплатный план; Standard от $69/месяц; Professional от $249/месяц.
3. Apify: маркетплейс Actor плюс кастомные скраперы
Apify — платформа для разработчиков, построенная вокруг «Actors» — готовых или кастомных скриптов скрейпинга, которые вы разворачиваете и запускаете в облаке Apify. Actor Store содержит тысячи готовых скраперов для сайтов вроде Amazon, Google Maps, LinkedIn и Instagram, что делает его сильным выбором, когда ваш мультисайтовый список пересекается с их каталогом.
Для сайтов без готового actor вы пишете свой на JavaScript или Python и хостите на инфраструктуре Apify. Эта двойная модель (маркетплейс плюс кастом) позволяет Apify масштабироваться на разнообразные мультисайтовые проекты.
Тип: Платформа для разработчиков с маркетплейсом Actor.
Лучше всего для: Команд разработчиков, которым нужны готовые скраперы там, где они есть, и кастомные Actors там, где их нет.
Ключевые возможности:
- Тысячи готовых Actors для крупных сайтов;
- Управление прокси, планирование и мониторинг из коробки;
- Custom Actor SDK на Python и JavaScript;
- Интеграции с Make, Zapier и webhooks.
Плюсы: Огромный каталог сокращает время разработки. Сильный dev tooling. Предсказуемый pay-as-you-go.
Минусы: Накладные расходы на поддержку при изменении целевых сайтов. Стоимость растёт при тяжёлых нагрузках.
Цены: Бесплатный план; Starter $29/месяц; Scale $199/месяц.
4. Bright Data: корпоративная мультисайтовая data-инфраструктура
Bright Data — тяжеловес веб-data-инфраструктуры. Помимо Web Scraper IDE, визуальной среды для создания JS-скраперов, Bright Data предлагает Datasets Marketplace с предсобранными данными с крупных публичных сайтов, а также residential и ISP proxy-сети и инфраструктуру разблокировки. Это избыточно для мелких задач, но не имеет равных на масштабе.
Тип: Корпоративная data-инфраструктура плюс визуальная IDE.
Лучше всего для: Крупномасштабного критически важного мультисайтового сбора с агрессивными антибот-целями.
Ключевые возможности:
- Web Scraper IDE с визуальными и кодовыми workflow;
- Datasets Marketplace для предсобранных данных;
- Residential, ISP и mobile proxy-сети;
- Unblocking API для сильно защищённых целей.
Плюсы: Лучшая в классе proxy-инфраструктура. Предсобранные датасеты экономят недели для распространённых целей.
Минусы: Корпоративные цены. Крутая кривая обучения.
Цены: По использованию, премиум-уровень. Индивидуальные котировки для больших объёмов. Scraper API от $0.75/1k rec.
5. ScrapingBee: один API-вызов, любой сайт
ScrapingBee — scraping API, который обрабатывает JS-рендеринг, ротацию прокси и оркестрацию headless-браузера за одним HTTP endpoint. Отправьте URL — получите чистый HTML или структурированный JSON для поддерживаемых endpoint вроде Amazon, SERP и недвижимости. Для мультисайтовой работы главное преимущество — единый интерфейс: один и тот же API-вызов на сотнях сайтов.
Тип: Scraping API с JS-рендерингом.
Лучше всего для: Разработчиков, которым нужен один API вместо поддержки парка браузеров.
Ключевые возможности:
- Автоматический JS-рендеринг;
- Ротация residential и datacenter прокси;
- Готовые endpoint для Amazon и SERP;
- Простые HTTP / Python / Node SDK.
Плюсы: Самая простая API-интеграция. Предсказуемое ценообразование за запрос.
Минусы: Тяжёлые JS-страницы быстро съедают кредиты. Менее гибкий, чем полноценные фреймворки для edge cases.
Цены: От $49/месяц за ~250K кредитов.
6. Browse.ai: обучайте роботов следить за страницами
Browse.ai позволяет записать путь по сайту (клики, выбор, пагинация) и сохранить его как «робота», которого можно перезапускать по расписанию. Для мультисайтового мониторинга (отслеживание цен конкурентов на 20 сайтах, наблюдение за job boards на новые вакансии) сложно найти быстрее по скорости настройки.
Тип: UI-скрапер с обучением робота.
Лучше всего для: Повторяющегося мониторинга конкретных мультисайтовых целей.
Ключевые возможности:
- Обучение робота point-and-click;
- Готовые роботы для распространённых сайтов;
- Запуски по расписанию с уведомлениями email/Slack;
- Интеграции с Google Sheets, Airtable, Zapier.
Плюсы: По-настоящему дружелюбен новичкам. Силён в workflow мониторинга.
Минусы: Менее гибок для сложной логики извлечения. Каждый робот — на один сайт, поэтому мультисайтовые проекты требуют одного робота на цель.
Цены: 100 бесплатных ежедневных кредитов; платные планы от $16/месяц.
7. ParseHub: визуальный скрапер с щедрым бесплатным тарифом
ParseHub — desktop визуальный скрапер, который обрабатывает AJAX, бесконечную прокрутку и сценарии входа через point-and-click интерфейс. У него заметно щедрый бесплатный тариф (200 страниц за запуск, 5 публичных проектов), что делает его выбором для разовых мультисайтовых исследовательских проектов с ограниченным бюджетом.
Тип: Desktop визуальный скрапер.
Лучше всего для: Мультисайтовых проектов на бесплатном тарифе со средней сложностью.
Ключевые возможности:
- Визуальный point-and-click конструктор workflow;
- Обрабатывает JS, AJAX, бесконечную прокрутку;
- Доступ к API на платных планах;
- Облачные запуски на тарифе Standard и выше.
Плюсы: Сильный бесплатный план. Лучше большинства визуальных скраперов справляется с динамическим контентом.
Минусы: Медленнее облачных конкурентов. Только desktop на бесплатном тарифе.
Цены: Бесплатно; Standard $189/месяц; Professional $599/месяц.
8. Zyte: Scrapy плюс управляемая инфраструктура
Zyte — компания за Scrapy, самым используемым open-source Python-фреймворком для скрейпинга. Их коммерческий продукт оборачивает Scrapy управляемым runtime, AI-извлечением и глобальной proxy-сетью. Если ваша команда уже живёт в Scrapy, Zyte — путь от «запуска пауков на ноутбуке» к «запуску на масштабе».
Тип: Scrapy плюс управляемая инфраструктура плюс AI-извлечение.
Лучше всего для: Инженерных команд, масштабирующих существующие Scrapy-проекты на множество сайтов.
Ключевые возможности:
- Scrapy Cloud для хостинга пауков;
- Smart Proxy Manager с ротацией IP;
- Automatic Extraction API (на базе AI);
- Задержка менее 100 мс на глобальном edge.
Плюсы: Без штрафов за превышение; избыточное использование тарифицируется со скидкой. Сильная dev-экосистема.
Минусы: Более крутая кривая обучения для тех, кто не знаком со Scrapy.
Цены: Pay-as-you-go от $0.13–$1.27 за 1K HTTP-ответов; объёмные коммиты от $0.06/1K.
9. Scrapy: open-source рабочая лошадка
Scrapy — бесплатный open-source Python-фреймворк для создания масштабируемых веб-краулеров. Он асинхронный, экономичен по памяти и проверен в крупных мультисайтовых проектах. Без цены, без привязки к вендору. Просто код.
Тип: Open-source Python-фреймворк.
Лучше всего для: Инженерных команд, создающих кастомные краулеры на множестве сайтов.
Ключевые возможности:
- Асинхронный, высокая пропускная способность;
- Расширяемая система middleware;
- Встроенные pipelines и экспорт items;
- Огромное сообщество и экосистема библиотек.
Плюсы: Бесплатно. Проверен в бою. Непревзойдённая гибкость.
Минусы: Нужен Python. Нет GUI. Операционка на вас.
Цены: Бесплатно.
10. Playwright: автоматизация браузера для сложных сайтов
Playwright — open-source фреймворк автоматизации браузера от Microsoft. Он управляет Chromium, Firefox и WebKit в headless-режиме, обрабатывает сайты с тяжёлым JavaScript и поддерживает Python, Node.js, Java и .NET. Для мультисайтовых проектов, где часть целей сильно рендерится на JS или защищена входом, Playwright обычно — ответ.
Тип: Open-source автоматизация браузера.
Лучше всего для: Инженеров, скрейпящих сайты с тяжёлым JS или защитой входа.
Ключевые возможности:
- Поддержка нескольких браузеров и языков;
- Перехват сети и мокирование запросов;
- Автоожидание элементов (меньше флаков, чем у Selenium);
- Codegen для быстрых черновиков скраперов.
Плюсы: Бесплатно. Надёжен на сложных сайтах. Современный API.
Минусы: Ресурсоёмкий. Оркестрацию пишете сами.
Цены: Бесплатно.
Как обрабатывать CAPTCHA на разных сайтах?
CAPTCHA на разных сайтах обрабатывают, направляя каждую проверку через единый сервис решения — независимо от того, какого вендора CAPTCHA использует сайт. Тогда вашему скраперу всё равно, попал ли он на reCAPTCHA на одном сайте и Cloudflare Turnstile на следующем. Оба случая возвращаются как токен для вставки.
В мультисайтовом пайплайне вы обычно увидите следующее:
- Google reCAPTCHA v2 / v3 / Enterprise: наиболее распространённая;
- Cloudflare Turnstile: быстро растущая доля;
- DataDome / Imperva (Incapsula): премиальный e-commerce и travel;
- GeeTest / Tencent CAPTCHA: распространены на азиатских сайтах;
- hCaptcha / Prosopo / Altcha: privacy-focused альтернативы.
Попытка прикрутить разовый решатель к каждому скраперу — то, что убивает мультисайтовые пайплайны. Единый сервис вроде CapMonster Cloud предоставляет один API, который обрабатывает все основные типы CAPTCHA. Ваш скрапер отправляет URL страницы и site key, получает решённый токен и продолжает.
Несколько практических советов по мультисайтовой обработке CAPTCHA:
- Обнаруживайте рано и решайте один раз. Встройте обнаружение CAPTCHA в обработчик ответов скрапера, чтобы не парсить неудачные страницы.
- Кэшируйте решённые токены там, где сайт позволяет. Некоторые токены CAPTCHA остаются валидными минуты. Переиспользуйте их в этом окне.
- Следите за процентом неудач по каждой цели. Сайт, у которого внезапно падает успешность CAPTCHA, обычно тестирует новые бот-сигналы. Ротируйте fingerprint stack, прежде чем направлять больше трафика.
Как выглядит практический workflow запуска веб-скрапера на 50+ сайтах?
Практический workflow запуска веб-скрапера на 50+ сайтах сочетает подходящий скрапер для каждого типа сайта с единым proxy-слоем, единым слоем решения CAPTCHA и шагом дедупликации и экспорта, который нормализует вывод. Каждый сайт становится плагином, а не переписыванием с нуля.
Вот архитектура верхнего уровня, которую мы рекомендуем.
Пошагово:
Сегментируйте список целей. Группируйте сайты по сложности. Статические и шаблонные сайты можно отдать no-code скраперу вроде Octoparse. Высокодинамичные или нестандартные вёрстки — AI web scraping agent, где вы просто описываете на простом английском, что нужно. Сайты с входом и тяжёлым JS — на Playwright или managed API вроде Bright Data.
Стандартизируйте схему вывода. Заранее определите, какие колонки нужны каждой записи (source_url, title, price_usd, scraped_at). Заставьте каждый скрапер выдавать эту схему. Несовпадающие колонки — там, где мультисайтовые пайплайны разваливаются.
Централизуйте ротацию прокси. Используйте одного residential proxy-провайдера для всех скраперов. Прокси на каждый скрапер создают слепые зоны и неравномерное качество сессий.
Централизуйте решение CAPTCHA. Направляйте каждую встречу с CAPTCHA через один API. CapMonster Cloud или аналог даёт единый token endpoint для каждого типа CAPTCHA, который видят ваши скраперы.
Ограничивайте rate per-site, а не глобально. Глобальный rate limit замедляет быстрые сайты до скорости медленных. Лимиты per-site учитывают толерантность каждой цели.
Дедуплицируйте при приёме. Хешируйте записи по стабильному ключу (source_url + product_id), прежде чем они попадут в хранилище.
Мониторьте успешность по каждому сайту. Отслеживайте успешность скрейпинга как KPI per-site. Внезапное падение обычно означает, что сайт внедрил новую бот-защиту, а не что ваш скрапер «сломался».
Что я заметил, когда мы внедрили эту архитектуру в проекте на 38 сайтов, о котором говорил в начале: большая часть нагрузки по поддержке сместилась с «починки скраперов» на «наблюдение за графиком успешности per-site». Когда показатель сайта проседал, мы точно знали, какой скрапер трогать. Остальные продолжали работать.
Чего избегать:
• Один мега-скрапер на все сайты. Разные проблемы — разные инструменты.
• Жёстко заданные селекторы, когда семантическое AI-извлечение обобщается лучше.
• Пропуск юридической проверки. Скрейпите только публичные данные, уважайте robots.txt и terms of service и никогда не собирайте персональные данные без законного основания.
Заключение: выбор подходящих инструментов веб-скрейпинга для мультисайтовых данных
Лучшие инструменты веб-скрейпинга для мультисайтового извлечения данных в 2026 году — не одна категория. Это стек. Нетехнические пользователи, запускающие пакеты в десятки тысяч записей, получают максимальный эффект от AI-скрапера вроде Chat4Data. Команды с повторяющимся скрейпингом на похожих вёрстках выигрывают с шаблонами Octoparse. Инженерные команды, обрабатывающие миллионы записей, живут в Scrapy, Zyte или Bright Data.
Паттерн, который ломает пайплайны — один инструмент на всё. Паттерн, который масштабируется — подбор инструментов под типы сайтов, централизация прокси и решения CAPTCHA и отношение к каждому сайту как к plug-in модулю за нормализованной схемой.
Выберите веб-скрапер под наименьшую единицу вашей задачи. Стандартизируйте всё вокруг него. Добавьте аккаунт CapMonster Cloud в стек до того, как скраперы упрются в первую стену, а не после.
NB: Веб-скрейпинг следует использовать только для автоматизации тестирования на собственных сайтах и на сайтах, к которым у вас есть законный доступ. Всегда уважайте robots.txt, terms of service и применимые законы о защите данных.






