 CapMonster Cloud API
CapMonster Cloud API Extensão para navegadores
Extensão para navegadores reCAPTCHA
reCAPTCHA Cloudflare
Cloudflare Text Captcha
Text Captcha Amazon
Amazon
Rastreamento da Web com Python: Guia Completo
Rastreamento da Web é uma maneira útil de coletar dados da internet, frequentemente utilizada para indexação de sites, monitoramento de mudanças ou coleta de grandes volumes de informações. Neste artigo, vamos abordar os fundamentos do rastreamento da Web, apresentar ferramentas e bibliotecas úteis em Python e mostrar exemplos simples para ajudá-lo a começar!
Rastreamento da Web é o processo de busca automática na internet para coletar informações de sites. Ele envolve a exploração de várias páginas em um único site (ou até mesmo em sites diferentes) para reunir grandes volumes de dados. Rastreadores em larga escala são utilizados por mecanismos de busca e outras empresas para indexação de sites e coleta de dados para diversos fins.
Por exemplo, o Googlebot visita bilhões de páginas todos os dias, seguindo links entre páginas e sites para manter os resultados de pesquisa do Google atualizados. O Googlebot começa visitando alguns URLs-chave e, em seguida, segue os links nessas páginas para descobrir novos conteúdos. Ele utiliza algoritmos inteligentes para decidir quais páginas indexar e com que frequência, garantindo aos usuários os resultados de pesquisa mais relevantes.
Python é uma excelente escolha para rastreamento da Web porque é fácil de aprender e possui diversas bibliotecas úteis. Ferramentas como Scrapy, BeautifulSoup e Selenium simplificam o processo de rastreamento de sites e coleta de dados, independentemente da complexidade da tarefa.
Rastreamento da Web e raspagem da Web estão intimamente relacionados, mas não são a mesma coisa.
O rastreamento da Web funciona como uma aranha que se move de página em página dentro de um site (ou até mesmo entre vários sites) para coletar dados. Ele é mais voltado para a exploração e indexação de grandes volumes de informações, geralmente seguindo links entre páginas.
Já a raspagem da Web foca na extração de dados específicos de uma página da Web. É como dar zoom em um detalhe — por exemplo, coletar preços de produtos, informações de contato ou textos de uma página ou de um conjunto de páginas.
Em resumo, o rastreamento busca e coleta dados de várias páginas, enquanto a raspagem extrai informações específicas dessas páginas.
Vamos ver um exemplo de como um rastreador básico coleta informações de um site.
Início com a Seed URL
Imagine que você deseja coletar informações sobre postagens de blog em um site. A sua URL inicial (Seed URL) pode ser a página principal do blog, como por exemplo https://example.com.
Solicitação da página web
O rastreador envia uma solicitação HTTP para https://example.com, pedindo que o servidor retorne o conteúdo HTML da página principal. O servidor responde enviando o HTML dessa página.
Análise do conteúdo HTML
O rastreador então faz a análise do HTML da página principal. Ele procura por elementos específicos, como links para postagens de blog (que geralmente estão contidos em tags <a>) e outras informações úteis, como títulos de páginas ou metadados.
Extração de links
Da página principal, o rastreador encontra links para outras páginas — por exemplo, encontra os seguintes links:
https://example.com/blog/post1
https://example.com/blog/post2
https://example.com/about
O rastreador adiciona esses links à sua lista de páginas para visitar.
Seguindo os links
Agora o rastreador solicita a primeira postagem do blog, https://example.com/blog/post1. Ele envia outra solicitação HTTP e recebe o conteúdo HTML dessa página.
Analisando a postagem do blog
Na página da postagem do blog, o rastreador busca por links adicionais (como links para outras postagens de blog, categorias ou tags) e dados (como o título da postagem, autor e data de publicação). Esses dados são extraídos e salvos.
Extração de links adicionais
Da página https://example.com/blog/post1, o rastreador encontra links para outras postagens:
https://example.com/blog/post3
https://example.com/blog/post4
Esses novos links são adicionados à lista de URLs para o rastreamento.
Armazenamento de dados
O rastreador coleta o título da postagem, o autor, a data e o conteúdo da página https://example.com/blog/post1 e os armazena em um formato estruturado, como em um banco de dados ou arquivo CSV.
Evitação de duplicação
O rastreador monitora os URLs que ele já visitou. Se ele encontrar novamente https://example.com/blog/post1, ele irá ignorá-lo para evitar o rastreamento repetido da mesma página.
Antes de começar o rastreamento, o rastreador verifica o arquivo robots.txt em https://example.com/robots.txt para garantir que ele tem permissão para escanear o site. Se o arquivo bloquear o rastreamento de certas áreas do site (como o painel de administração), o rastreador evita essas áreas.
O rastreador continua esse processo, visitando páginas, extraindo links e coletando dados até que ele tenha coletado todas as informações do site ou atinja o limite estabelecido.
Esse processo básico permite que o rastreador colete grandes volumes de dados do site, seguindo links e coletando o conteúdo necessário de forma automática.
Python oferece uma ampla variedade de bibliotecas poderosas para rastreamento da Web, tanto padrão quanto de terceiros, que facilitam a coleta de dados de sites. Aqui está uma visão geral das bibliotecas padrão e de algumas opções populares de terceiros que podem ser usadas para rastreamento da Web:
- Bibliotecas padrão
urllib
urllib é uma biblioteca embutida do Python que oferece funções para trabalhar com URLs. Ela pode ser usada para enviar solicitações HTTP, analisar URLs e processar respostas. Embora não seja especificamente projetada para rastreamento da Web, ela permite carregar páginas, tornando-a uma ferramenta básica para crawlers simples.
http.client
http.client é outra biblioteca padrão que pode ser usada para processar solicitações HTTP. Ela oferece mais controle sobre o ciclo de solicitação/resposta e permite uma abordagem mais flexível para obter dados.
- Bibliotecas de terceiros
Requests
A biblioteca requests é uma das bibliotecas de terceiros mais populares para enviar solicitações HTTP em Python. Ela simplifica o processo de interação com páginas da Web e é frequentemente usada para tarefas de raspagem da Web e rastreamento. Requests facilita o manuseio de solicitações GET, POST e outras solicitações HTTP.
BeautifulSoup
Embora o BeautifulSoup por si só não seja um crawler, ele é frequentemente usado em conjunto com crawlers para analisar e extrair dados de páginas HTML. Ele facilita a navegação e a busca na árvore do documento, extração de links e análise de conteúdo.
Scrapy
Scrapy é uma poderosa e flexível framework para rastreamento da Web, projetado especificamente para tarefas de raspagem e rastreamento em grande escala. Ele permite definir spiders (crawlers) que podem percorrer sites automaticamente e extrair dados. Scrapy abrange tudo, desde o envio de solicitações até o armazenamento dos dados extraídos, tornando-o ideal para projetos mais complexos de rastreamento.
Selenium
Selenium é mais conhecido como uma ferramenta para automação de navegadores para testes de aplicativos web, mas também é frequentemente usado no rastreamento da Web ao trabalhar com páginas dinâmicas (sites com uso intensivo de JavaScript). Ele pode interagir com JavaScript e carregar conteúdo que não está visível imediatamente no HTML original.
A biblioteca re em Python é útil para extrair, processar e manipular texto durante o rastreamento da Web. Veja como ela pode ajudar:
- Extração de links: use expressões regulares para encontrar todos os atributos href (links) em uma página HTML.
- Extração de dados: extraia facilmente dados específicos, como preços ou nomes de produtos, usando padrões.
- Limpeza de dados: remova espaços indesejados ou tags do conteúdo extraído.
- Processamento de conteúdo dinâmico: extraia dados incorporados no JavaScript ou em estruturas HTML complexas.
- Filtragem de elementos: procure elementos com atributos específicos (como classe ou ID) usando padrões.
Embora as expressões regulares sejam poderosas e rápidas, elas devem ser usadas com cuidado, pois podem ser difíceis de depurar e não são adequadas para todas as tarefas de análise de HTML.
Neste tutorial, vamos passar pelo processo de criação de um rastreador simples na Web com Python. Este rastreador visitará um site, extrairá links e os seguirá para coletar dados adicionais. Vamos usar a biblioteca requests para carregar as páginas e o BeautifulSoup para fazer o parsing do HTML. Neste exemplo, o rastreador começará com https://www.wikipedia.org/ e coletará todos os links encontrados em cada página, navegando pelo site.
Antes de começar, certifique-se de ter:
- Python 3+: Baixe o instalador no site oficial, execute-o e siga as instruções para instalar.
- IDE para Python: Você pode usar o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
- Documentação de requests e BeautifulSoup: Consulte a documentação oficial para entender melhor como elas funcionam.
- Instalação das bibliotecas necessárias
Antes de começar, você precisa instalar as bibliotecas necessárias: requests e BeautifulSoup. Você pode instalá-las com pip:
pip install requests beautifulsoup4- Configuração de logs
A configuração de logs ajudará a acompanhar as ações do rastreador. Vamos configurar um log básico para exibir mensagens úteis enquanto o rastreador está em execução. Isso definirá o formato do log e o nível de log como INFO, o que exibirá mensagens importantes.
import logging
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s', level=logging.INFO
)- Criação da classe do rastreador
O rastreador estará contido em uma classe chamada SimpleCrawler. Nessa classe, definiremos métodos para carregar páginas, extrair links e gerenciar o processo de rastreamento.
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
self.visited: Conjunto para rastrear os URLs que já visitamos.self.to_visit: Lista contendo os URLs que ainda precisam ser visitados.Carregando a página web
O próximo passo é criar um método para carregar o conteúdo da página usando a biblioteca requests.
def fetch_page(self, url):
"""Carregar o conteúdo da página."""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Falha ao carregar {url}: {e}")
return NoneO método fetch_page envia uma solicitação GET para o URL especificado. Se a solicitação for bem-sucedida, ele retorna o conteúdo HTML da página. Caso contrário, registra um erro e retorna None.
- Extraindo links da página
Agora precisamos extrair links (URLs) do HTML da página. Usaremos o BeautifulSoup para fazer o parsing do HTML e encontrar todas as tags <a> com o atributo href.
from urllib.parse import urljoin
def extract_links(self, url, html):
"""Extrair e retornar todos os links da página."""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
yield full_url- BeautifulSoup(html, 'html.parser') faz o parsing do conteúdo HTML.
- soup.find_all('a', href=True) encontra todas as tags <a> com o atributo href.
- urljoin(url, link) garante que os URLs relativos sejam convertidos corretamente em absolutos.
6. Adicionando URLs à fila
Precisamos adicionar novos URLs à lista de URLs a serem visitadas, mas somente se ainda não foram visitados.
def add_to_queue(self, url):
"""Adicionar URL à lista de URLs a visitar, se ainda não foi visitado ou adicionado à fila."""
if url not in self.visited and url not in self.to_visit:
self.to_visit.append(url)Este método garante que não vamos visitar novamente URLs que já foram processados ou adicionados à fila.
7. Processamento de cada página
Agora, vamos escrever um método para processar cada página. Ele vai carregar a página, extrair links e adicioná-los à fila.
def process_page(self, url):
"""Processar página e coletar links."""
logging.info(f'Processando: {url}')
html = self.fetch_page(url)
if html:
for link in self.extract_links(url, html):
self.add_to_queue(link)Este método chama o fetch_page para carregar o conteúdo da página e depois extrai e adiciona os links encontrados à fila.
8. Loop de rastreamento
O loop principal continuará até que todos os URLs tenham sido visitados. Ele vai extrair URLs da lista to_visit, processá-los e marcá-los como visitados.
def crawl(self):
"""Rastrear a web a partir dos URLs iniciais."""
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
self.process_page(url)
self.visited.add(url)O loop continuará até que não haja mais URLs para visitar. Cada URL será processado, links serão extraídos e adicionados à fila. Após o processamento, o URL será marcado como visitado.
9. Executando o rastreador
Por fim, vamos criar uma instância da classe SimpleCrawler e iniciar o rastreamento a partir de uma lista de URLs fornecida.
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
crawler.crawl()Este código inicializa o rastreador com a lista de URLs iniciais e começa o processo de rastreamento.
Exemplo de código completo:
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
def fetch_page(self, url):
"""Carregar o conteúdo da página."""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Falha ao carregar {url}: {e}")
return None
def extract_links(self, url, html):
"""Extrair e retornar todos os links da página."""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
yield full_url
def add_to_queue(self, url):
"""Adicionar URL à lista de URLs a visitar, se ainda não foi visitado ou adicionado à fila."""
if url not in self.visited and url not in self.to_visit:
self.to_visit.append(url)
def process_page(self, url):
"""Processar página e coletar links."""
logging.info(f'Processando: {url}')
html = self.fetch_page(url)
if html:
for link in self.extract_links(url, html):
self.add_to_queue(link)
def crawl(self):
"""Rastrear a web a partir dos URLs iniciais."""
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
self.process_page(url)
self.visited.add(url)
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
crawler.crawl()Exemplo de saída:
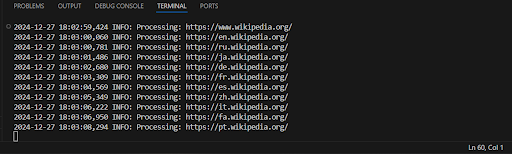
Este rastreador executa tarefas básicas de extração de links de páginas web, mas possui várias limitações que podem afetar seu desempenho, robustez e escalabilidade.
- Sem limite de profundidade ou páginas
O rastreador continuará a rastrear páginas indefinidamente, o que pode sobrecarregar o servidor ou levar a um loop infinito. - Processamento ineficiente de links
Todos os links encontrados são adicionados à fila de URLs para visitação, mas o rastreador não verifica se já foram processados anteriormente. - Raspagem de thread única (serializada)
O rastreador funciona em um único thread, o que torna a raspagem mais lenta em larga escala. - Falta de tratamento de erros ou gerenciamento de timeouts
O rastreador apenas registra o erro e continua a execução, o que poderia ser melhorado com a adição de uma lógica de tentativas. - Falta de verificação de robots.txt
O rastreador não verifica se a raspagem é permitida para o site. - Ausência de atrasos entre as requisições
O rastreador pode sobrecarregar o servidor devido à falta de atrasos entre as requisições, o que pode resultar em bloqueio. - Sem suporte a conteúdo dinâmico
O rastreador só funciona com conteúdo estático e não pode lidar com páginas que geram conteúdo por meio de JavaScript.
- Use multitarefa ou multithreading:
O uso de paralelismo (através de módulos como concurrent.futures ou asyncio para escaneamento assíncrono) pode acelerar significativamente o processo. Programas multithread podem processar várias páginas simultaneamente, aumentando a produtividade.
Exemplo: aiohttp e asyncio para requisições assíncronas.
- Use bibliotecas mais avançadas:
Scrapy: a biblioteca mais popular para rastreamento e coleta de dados na web, incluindo suporte integrado para paralelismo, gerenciamento de sessões, tratamento de erros e outras funcionalidades.
Playwright ou Selenium: adequados para lidar com páginas dinâmicas que utilizam JavaScript para gerar conteúdo.
Adicione lógica de verificação de profundidade recursiva ou limite de número de páginas visitadas para evitar loops infinitos.
- Introduza delays entre as requisições:
Adicionar delays aleatórios ou timeouts fixos entre as requisições ajuda a evitar sobrecarga no servidor e bloqueio do IP.
- Melhore o tratamento de erros e a lógica de tentativas:
Implemente mecanismos de tentativas para erros de rede ou erros do lado do servidor (como 500 ou 503). A biblioteca requests oferece suporte para tentativas através do urllib3.
- Use um banco de dados ou sistema de arquivos para gerenciar a fila:
Em vez de armazenar links na memória, utilize um banco de dados (como SQLite ou Redis) para gerenciar a fila, o que melhorará a escalabilidade.
- Processamento paralelo:
Use bibliotecas como Celery ou Dask para processamento distribuído, permitindo lidar com tarefas de rastreamento em grande escala.
Agora que entendemos as limitações do nosso código e nos familiarizamos com métodos mais eficientes, vamos reescrever o código para torná-lo mais eficaz:
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
self.found_links = []
def fetch_page(self, url):
"""Baixar o conteúdo da página."""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Não foi possível carregar {url}: {e}")
return None
def extract_links(self, url, html):
"""Extrair e processar todos os links da página especificada."""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
if full_url not in self.visited and full_url not in self.to_visit:
self.found_links.append(full_url)
def process_page(self, url):
"""Processar uma página e coletar links."""
html = self.fetch_page(url)
if html:
self.extract_links(url, html)
self.visited.add(url)
def crawl(self):
"""Rastreamento da web a partir dos URLs iniciais."""
with ThreadPoolExecutor(max_workers=10) as executor:
# Adicionar os URLs iniciais à fila
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
executor.submit(self.process_page, url)
# Aguardar a finalização do processamento de todas as páginas
executor.shutdown(wait=True)
return self.found_links
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
print("Links encontrados:")
for link in links:
print(link)Fizemos algumas melhorias no rastreador para aumentar sua velocidade e eficiência. Essas mudanças ajudarão a coletar links mais rapidamente e sem atrasos desnecessários.
O que foi alterado:
Multitarefa: Utilizado o ThreadPoolExecutor para carregar as páginas em paralelo, o que acelera a execução.
Coleta de todos os links de uma vez: Todos os links encontrados são salvos na lista found_links, e os resultados são exibidos após o processamento de todas as páginas.
Remoção de saídas intermediárias: O registro de logs para cada página foi removido para acelerar a execução.
Explicação:
- O ThreadPoolExecutor permite processar várias páginas ao mesmo tempo (em paralelo), o que acelera consideravelmente o processo, especialmente quando há muitas páginas.
- A lista found_links armazena todos os links encontrados nas páginas. Após o processamento de todas as páginas, esses links são exibidos.
Exemplo de saída:
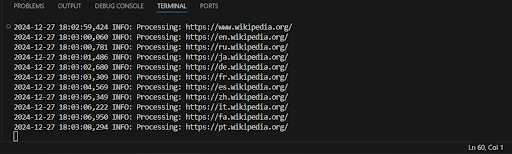
Uhul, agora nosso código funciona muito mais rápido e exibe todos os links encontrados de uma vez!
Após rodar o rastreador da web, é importante salvar os dados coletados. Uma das maneiras mais populares e simples de salvar os links encontrados é usar um arquivo JSON. O formato JSON é leve, fácil de ler e amplamente utilizado para troca de dados. Vamos ver como podemos salvar os links encontrados em um arquivo e discutir algumas formas de fazer isso.
Aqui está como você pode fazer isso usando o exemplo SimpleCrawler do código anterior:
import json
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
self.found_links = []
def fetch_page(self, url):
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Falha ao buscar {url}: {e}")
return None
def extract_links(self, url, html):
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
if full_url not in self.visited and full_url not in self.to_visit:
self.found_links.append(full_url)
def process_page(self, url):
html = self.fetch_page(url)
if html:
self.extract_links(url, html)
self.visited.add(url)
def crawl(self):
with ThreadPoolExecutor(max_workers=10) as executor:
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
executor.submit(self.process_page, url)
executor.shutdown(wait=True)
return self.found_links
def save_to_json(self, filename):
"""Salvar os links encontrados em um arquivo JSON."""
with open(filename, 'w', encoding='utf-8') as file:
json.dump(self.found_links, file, ensure_ascii=False, indent=4)
logging.info(f"Links encontrados salvos em {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Salvando os links em um arquivo JSON
crawler.save_to_json('found_links.json')
print("Os links encontrados foram salvos em 'found_links.json'")Após a execução, o código salvará os links em um arquivo found_links.json, que ficará assim:
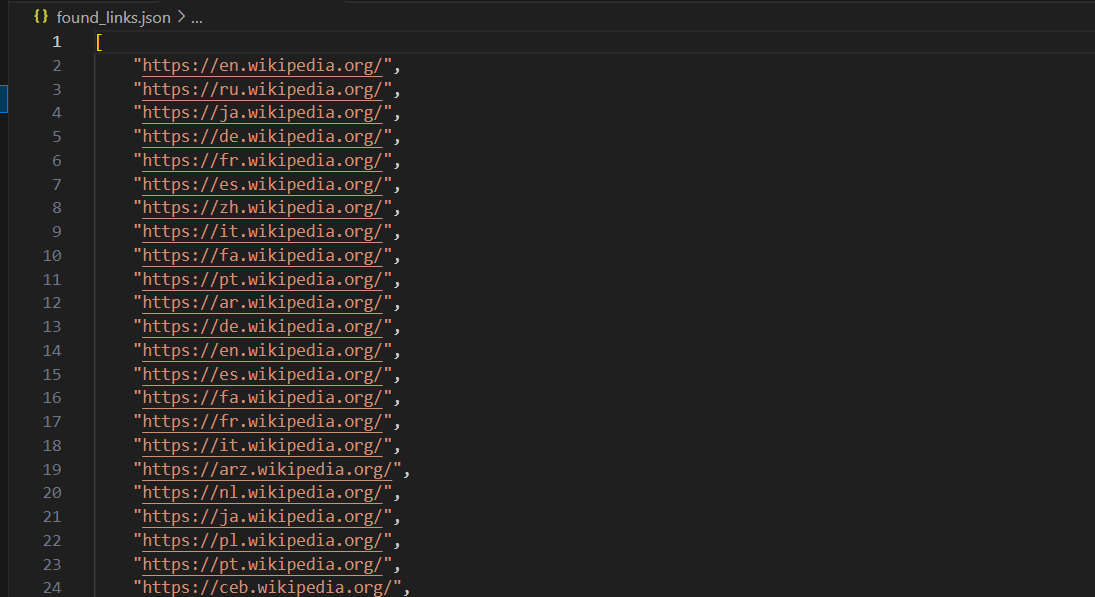
Além de salvar os links em um arquivo JSON, existem outras formas de armazenar os dados coletados durante o rastreamento da web. Aqui estão alguns métodos populares:
Salvando em um arquivo CSV
CSV (Comma-Separated Values) é um formato simples e amplamente utilizado para armazenar dados tabulares. Ele pode ser facilmente aberto no Excel ou no Google Planilhas.
import csv
class SimpleCrawler:
# Código anterior...
def save_to_csv(self, filename):
"""Salvar os links encontrados em um arquivo CSV."""
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['URL']) # Cabeçalho da coluna
for link in self.found_links:
writer.writerow([link])
logging.info(f"Links encontrados salvos em {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Salvando os links em um arquivo CSV
crawler.save_to_csv('found_links.csv')
print("Os links encontrados foram salvos em 'found_links.csv'")Salvando em um banco de dados (SQLite)
Se você deseja armazenar seus links em um banco de dados para facilitar as consultas, o SQLite é uma boa escolha. É um banco de dados leve que não exige um servidor separado e é bem adequado para armazenar dados de pequeno e médio porte.
import sqlite3
class SimpleCrawler:
# Código anterior...
def save_to_database(self, db_name):
"""Salvar os links encontrados em um banco de dados SQLite."""
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
# Criando a tabela, se ela ainda não existir
cursor.execute('''
CREATE TABLE IF NOT EXISTS links (
id INTEGER PRIMARY KEY AUTOINCREMENT,
url TEXT UNIQUE
)
''')
# Inserindo cada link no banco de dados
for link in self.found_links:
cursor.execute('INSERT OR IGNORE INTO links (url) VALUES (?)', (link,))
conn.commit()
conn.close()
logging.info(f"Links encontrados salvos em {db_name}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Salvando os links no banco de dados
crawler.save_to_database('found_links.db')
print("Os links encontrados foram salvos em 'found_links.db'")Salvando em um arquivo Excel (XLSX)
Se você prefere trabalhar com o Excel, pode salvar seus dados diretamente em um arquivo Excel usando a biblioteca openpyxl.
from openpyxl import Workbook
class SimpleCrawler:
# Código anterior...
def save_to_excel(self, filename):
"""Salvar os links encontrados em um arquivo Excel."""
workbook = Workbook()
sheet = workbook.active
sheet.append(['URL']) # Cabeçalho da coluna
for link in self.found_links:
sheet.append([link])
workbook.save(filename)
logging.info(f"Links encontrados salvos em {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Salvando os links em um arquivo Excel
crawler.save_to_excel('found_links.xlsx')
print("Os links encontrados foram salvos em 'found_links.xlsx'")Agora, vamos criar um crawler para o site Amazon.com usando Scrapy (antes de começar, consulte a documentação).
- Abra a página de resultados da busca da Amazon (por exemplo, https://www.amazon.com/s?k=phones) no seu navegador.
- Clique com o botão direito em qualquer parte da página e selecione "Inspecionar" (ou pressione Ctrl+Shift+I no Windows/Linux ou Cmd+Option+I no Mac). Isso abrirá a janela do DevTools, onde você pode explorar a estrutura da página.
- Agora, encontre os elementos que você precisa extrair, estudando o código HTML. Passe o cursor sobre o nome do produto na página da Amazon. No DevTools, o HTML correspondente será destacado. Clique com o botão direito no nome do produto e selecione "Inspecionar".
Preste atenção nas tags e atributos das classes. Por exemplo, o nome do produto pode estar dentro de um <span> dentro de uma tag de link (<a>) e ter uma classe específica (por exemplo, a-text-normal). Neste caso, o seletor CSS para extrair o nome do produto será o seguinte: a.a-link-normal.s-line-clamp-2.a-text-normal span::text.
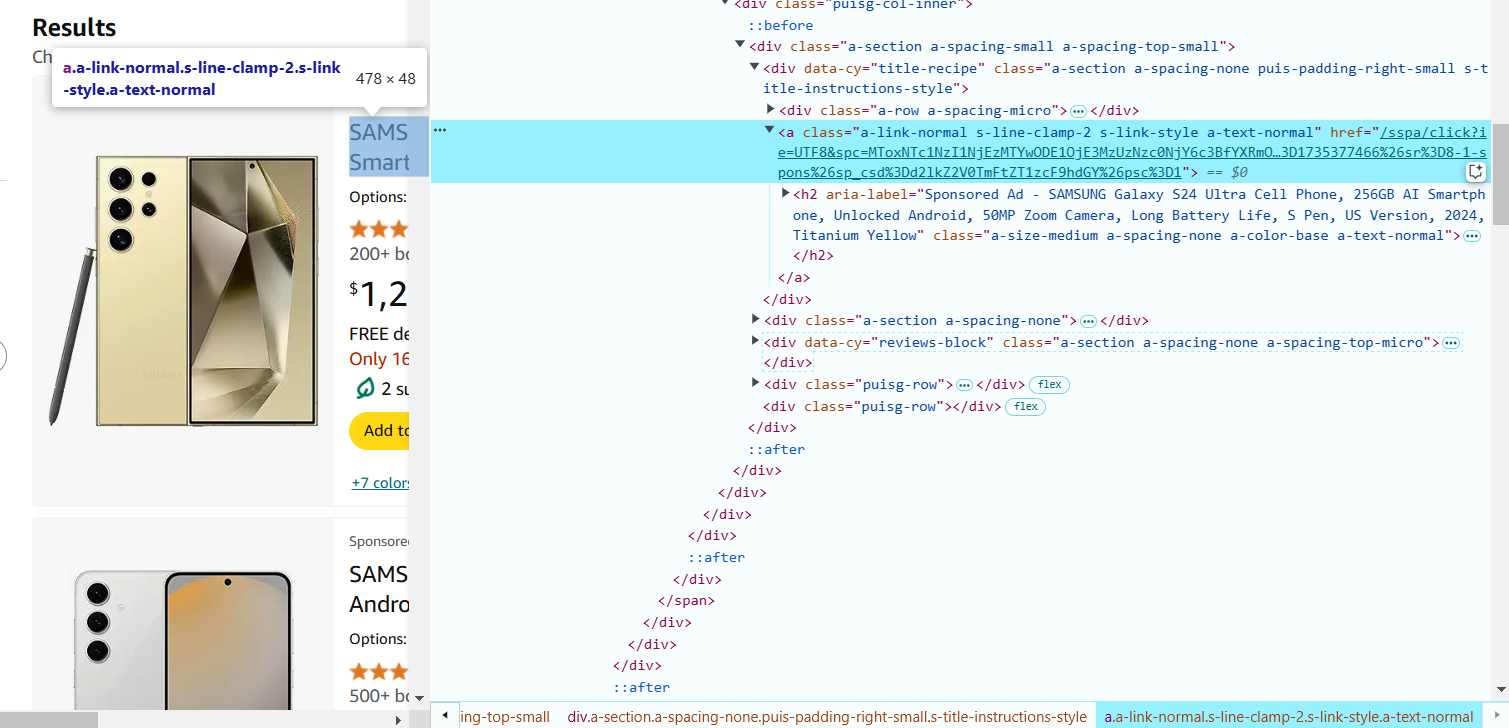
5. Passe o cursor sobre o preço do produto na página e clique com o botão direito para selecionar 'Inspecionar'. O preço pode estar dentro de uma tag <span> com uma classe, por exemplo, a-price-whole. O seletor CSS para extrair o preço: span.a-price-whole::text.
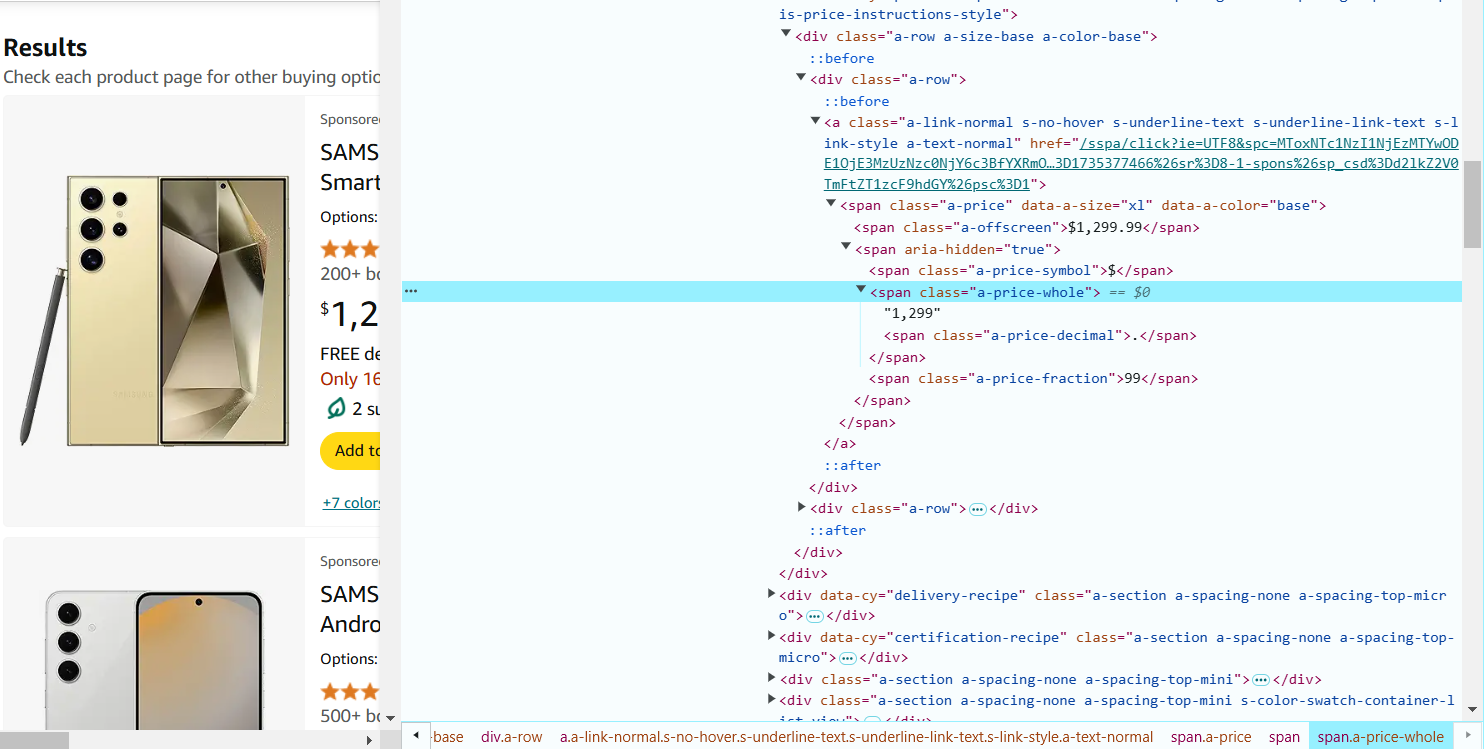
6. Passe o cursor sobre a avaliação do produto (estrelas) e clique com o botão direito para selecionar 'Inspecionar'. A avaliação geralmente está dentro da tag <i> com uma classe, por exemplo, a-icon-star-small. O seletor CSS para extrair a avaliação: i.a-icon-star-small span.a-icon-alt::text.
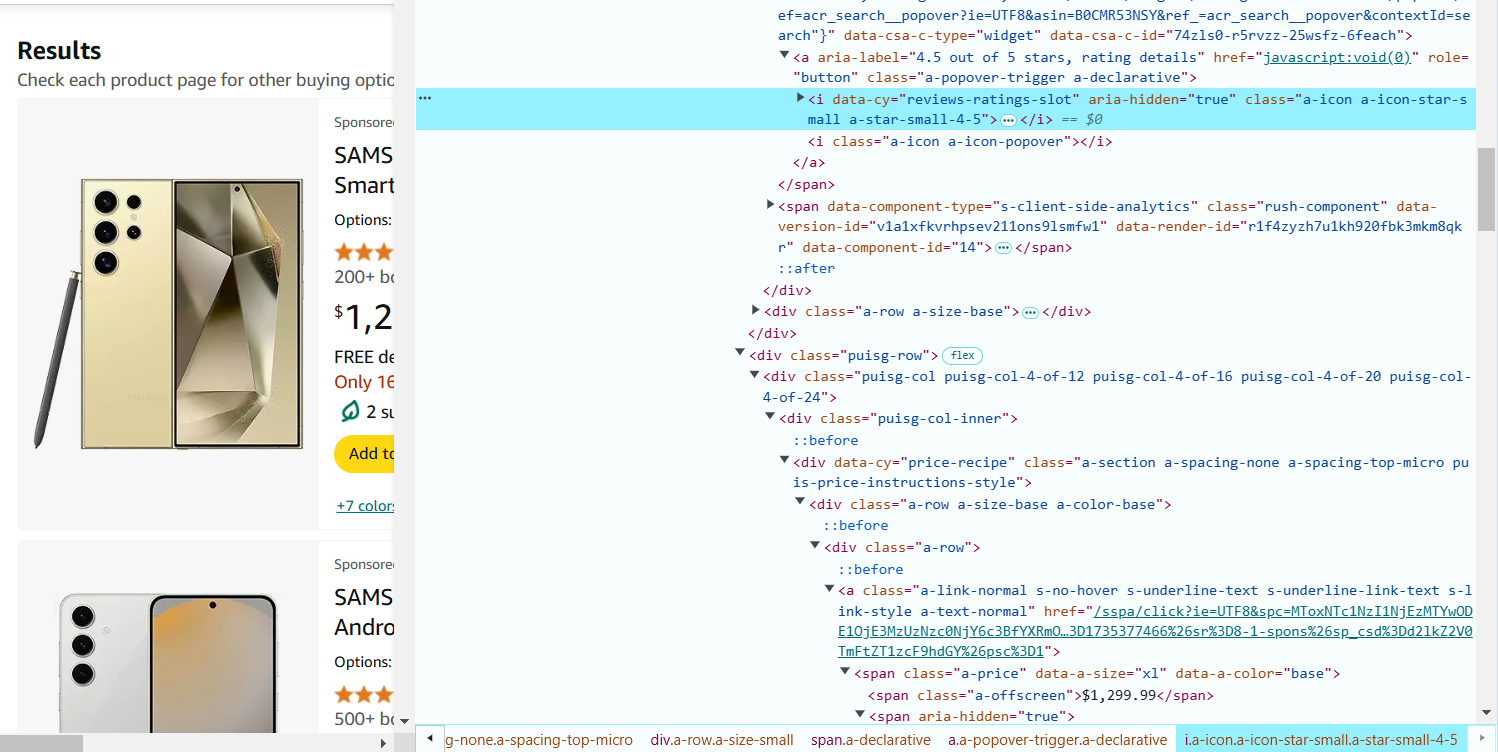
7. Passe o cursor sobre o número de avaliações e clique com o botão direito para selecionar 'Inspecionar'. O número de avaliações está na tag <span> com a classe a-size-base.s-underline-text. O seletor CSS para extrair o número de avaliações: span.a-size-base.s-underline-text::text.
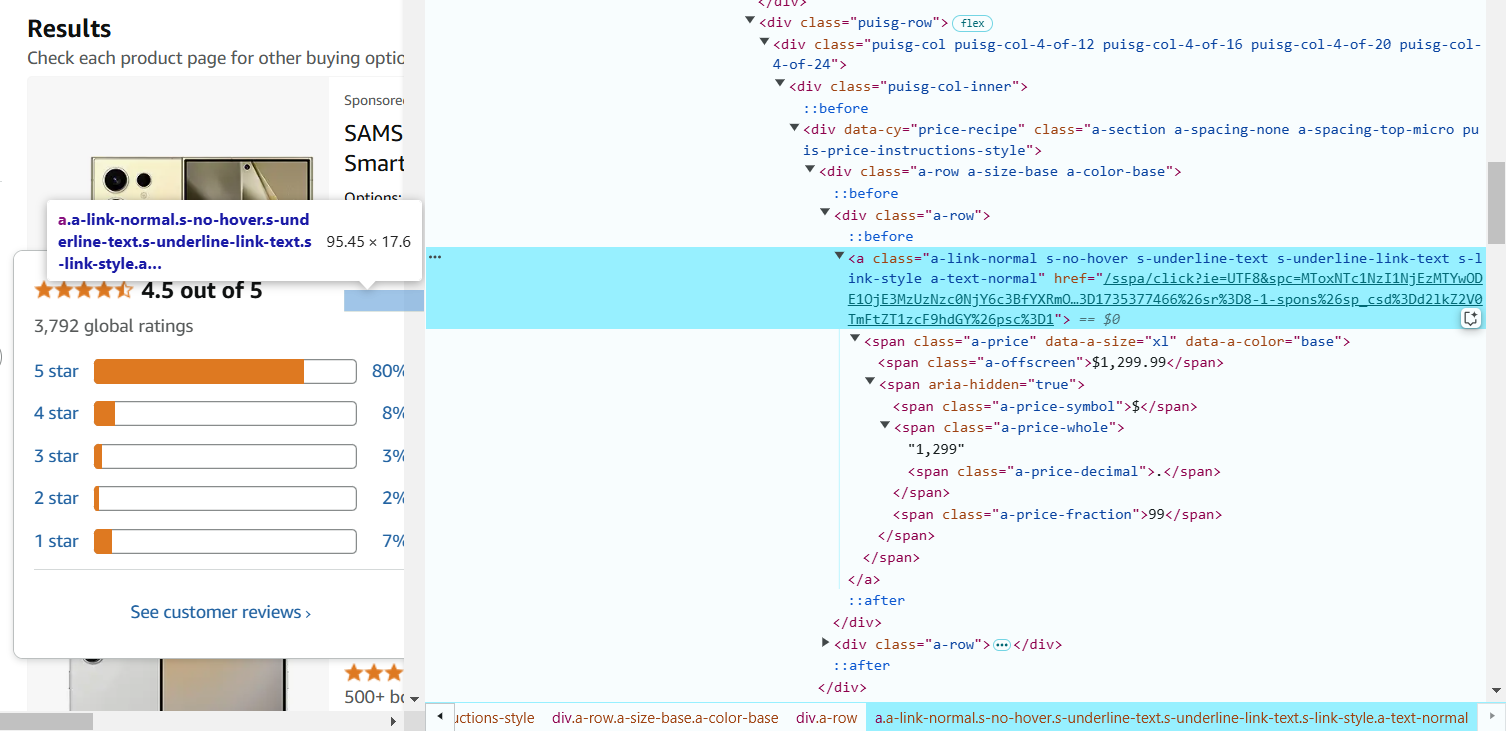
8. Najedź kursorem na nazwę produktu i kliknij prawym przyciskiem myszy, aby wybrać 'Inspect'. Link znajduje się w tagu <a>, a URL w atrybucie href. Seletor CSS do wyciągnięcia URL produktu: a.a-link-normal.s-line-clamp-2.s-link-style::attr(href).
9. Tworzenie pająka Scrapy
Teraz, gdy masz potrzebne selektory CSS, możesz ich użyć w pająku Scrapy do wyciągania danych.
import scrapy
class AmazonSpider(scrapy.Spider):
name = "ecommerce"
# Początkowy URL
start_urls = [
'https://www.amazon.com/s?k=phones'
]
def parse(self, response):
# Dodanie loga do debugowania
self.log(f"Parsing page: {response.url}")
# Wyciąganie szczegółów produktu
for product in response.css('div.s-main-slot div.s-result-item'):
# Wyciąganie nazwy produktu
name = product.css('a.a-link-normal.s-line-clamp-2.a-text-normal span::text').get()
if name: # Sprawdzenie obecności nazwy produktu
self.log(f"Found product: {name}")
# Wyciąganie ceny (może brakować u niektórych produktów)
price = product.css('span.a-price-whole::text').get()
# Wyciąganie oceny (może brakować u niektórych produktów)
rating = product.css('i.a-icon-star-small span.a-icon-alt::text').get()
# Wyciąganie liczby recenzji
reviews = product.css('span.a-size-base.s-underline-text::text').get()
# Wyciąganie URL produktu
product_url = product.css('a.a-link-normal.s-line-clamp-2.s-link-style::attr(href)').get()
yield {
'name': name,
'price': price,
'rating': rating,
'reviews': reviews,
'url': response.urljoin(product_url),
}
# Przejście do następnej strony
next_page = response.css('li.a-last a::attr(href)').get()
if next_page:
self.log(f"Following next page: {next_page}")
yield response.follow(next_page, self.parse)Wyjaśnienie kodu:
- start_urls: to URL, od którego zaczyna się parsowanie. W tym przypadku są to wyniki wyszukiwania na Amazonie dla telefonów.
- Metoda parse: ta metoda jest używana do wyciągania danych z odpowiedzi HTML. Używa selektorów CSS do znalezienia odpowiednich elementów.
- product.css('selector::text'): wyciąga tekstową zawartość z elementów pasujących do selektora.
- product.css('selector::attr(href)'): wyciąga atrybut href (URL) z tagu <a>.
- Paginacja: pająk przechodzi do następnej strony, używając linku next_page. Dzięki temu pająk zbiera wszystkie strony z produktami.
10. Uruchomienie pająka
Po utworzeniu pająka, zapisz plik w katalogu spiders w swoim projekcie Scrapy (np. amazon_spider.py).
scrapy crawl ecommerce -o products.jsonW zapisanym pliku, wyciągnięte informacje powinny wyglądać mniej więcej tak:
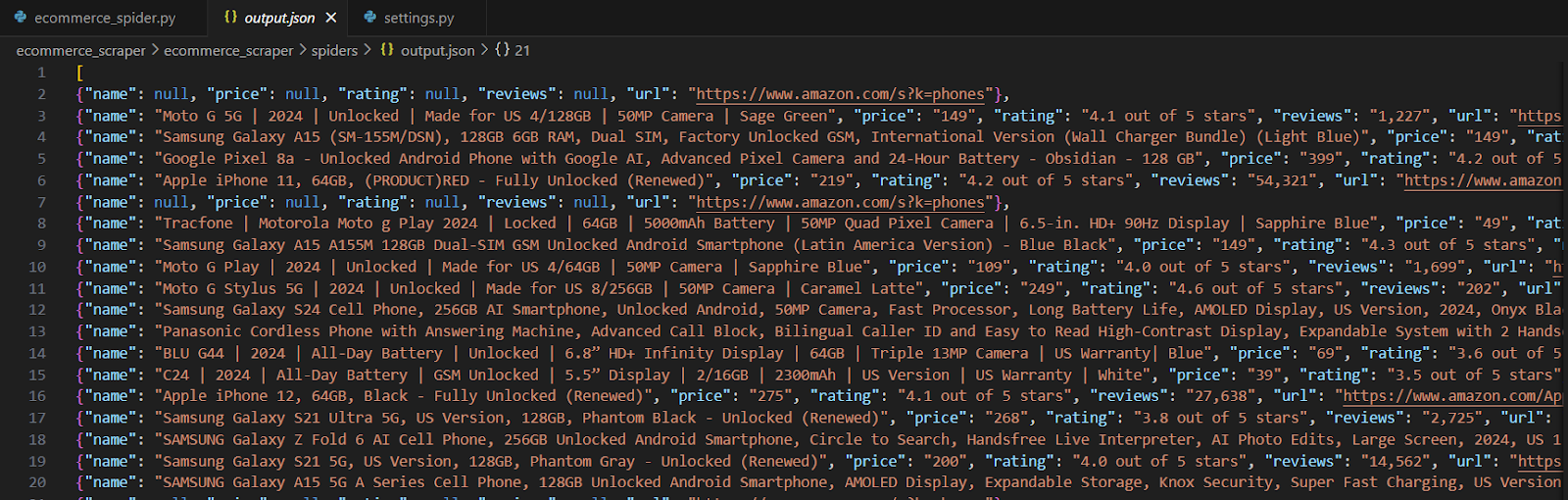
Observações importantes:
Sites de comércio eletrônico reais, como Amazon, eBay e outros, possuem mecanismos de proteção mais complexos contra scraping, incluindo CAPTCHA, limitação de taxa de requisições e conteúdo dinâmico. Para fazer scraping de sites reais, é necessário considerar esses fatores.
Sempre verifique o arquivo robots.txt do site e certifique-se de seguir sua política de scraping. O scraping deve ser feito de maneira ética, respeitando os termos de uso do site, para não sobrecarregar seus servidores com requisições excessivas. Também é importante garantir que qualquer dado coletado seja utilizado de acordo com as leis e regulamentações de privacidade, como o GDPR.
Sites reais frequentemente utilizam serviços como reCAPTCHA, DataDome ou Cloudflare para prevenir scraping automático. Nesses casos, você pode integrar ferramentas como CapMonster Cloud para contornar CAPTCHA automaticamente. O CapMonster Cloud oferece uma API simples para resolver diferentes tipos de CAPTCHA, incluindo o Google reCAPTCHA, Geetest e outros.
Sites podem monitorar atividades de scraping analisando impressões digitais do navegador, como User-Agent, Accept-Language e outros cabeçalhos. Para evitar a detecção, você deve alterar essas impressões digitais (por exemplo, usando serviços como BrowserStack ou ProxyCrawl) ou usar cabeçalhos personalizados e proxies dinâmicos.
Além disso, a rotação de endereços IP e o uso de serviços de proxy (como ScraperAPI ou ProxyMesh) pode ajudar a evitar bloqueios por um número excessivo de requisições a partir de um único IP.
Aqui está um exemplo de rastreamento dinâmico da web usando o Playwright. Este script extrai as últimas notícias do Hacker News (https://news.ycombinator.com/), um popular site de notícias de tecnologia que carrega conteúdo dinamicamente via JavaScript.
Por que usar isso?
Essa abordagem é perfeita para sites que não exibem todo o seu conteúdo imediatamente (eles o carregam via JavaScript). O Playwright permite que você aja como um usuário real, aguardando até que o conteúdo seja carregado antes de coletar os dados. É uma ótima ferramenta para sites dinâmicos modernos!
Instalação do Playwright
Se você ainda não o instalou, execute os seguintes comandos no seu terminal:
pip install playwright
playwright installPara baixar apenas o Chromium:
pip install playwright
playwright install chromiumExemplo de código:
from playwright.sync_api import sync_playwright
def dynamic_crawler():
with sync_playwright() as p:
# Iniciar o navegador
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Acessar o site
url = "https://news.ycombinator.com/"
page.goto(url)
# Aguardar o carregamento das notícias
page.wait_for_selector(".athing")
# Extrair os dados
articles = []
for item in page.query_selector_all(".athing"):
title = item.query_selector(".titleline a").inner_text()
link = item.query_selector(".titleline a").get_attribute("href")
rank = item.query_selector(".rank").inner_text() if item.query_selector(".rank") else None
articles.append({"rank": rank, "title": title, "link": link})
browser.close()
# Imprimir os resultados
for article in articles:
print(article)
# Executar o crawler
dynamic_crawler()O que o código faz
Iniciar o navegador: chromium.launch() inicia o navegador leve em segundo plano (o parâmetro headless=True significa que a janela do navegador não será exibida).
Acessar o site: page.goto(url) acessa o Hacker News.
Aguardar o conteúdo: page.wait_for_selector(".athing") aguarda até que os artigos sejam carregados.
Extrair dados: O código procura todas as notícias usando a classe CSS .athing. Para cada item, ele extrai:
- Classificação (por exemplo, "1.")
- Título da notícia
- Link para o texto completo do artigo.
Fechar o navegador: O navegador é fechado após a coleta dos dados.
Exibir os resultados: Cada artigo é exibido como um pequeno dicionário com chaves como classificação, título e link.
Exemplo de saída: Após a execução do script, o seu terminal exibirá algo assim:
{'rank': '1.', 'title': 'A great open-source project', 'link': 'https://example.com'}
{'rank': '2.', 'title': 'How to learn Python', 'link': 'https://news.ycombinator.com/item?id=123456'}
{'rank': '3.', 'title': 'Show HN: My new tool', 'link': 'https://example.com/tool'}O web crawling com Python é uma excelente maneira de coletar dados de sites e descobrir insights valiosos. Usando ferramentas como BeautifulSoup, Scrapy e Playwright, você pode trabalhar tanto com sites simples e estáticos quanto com sites mais complexos e dinâmicos. Os exemplos que exploramos mostram como extrair dados e lidar com desafios, como conteúdo em JavaScript e limitações de sites.
Se for necessário contornar bloqueios, métodos como o uso de proxies ou a resolução de CAPTCHA podem ajudar, mas é importante aplicá-los de maneira ética.
Com Python e as ferramentas certas, o web crawling se torna uma habilidade empolgante e poderosa. Não importa se você está começando ou já tem alguma experiência, é possível alcançar ótimos resultados e tornar seus projetos brilhantes. Boa sorte e aproveite o processo de crawling!

